1 Introduction
Tabular data—structured collections of records (rows) and attributes (columns)—underpins a vast array of real-world applications, from healthcare and finance to industrial analytics and scientific research. These datasets form the backbone of modern decision-making systems: hospitals rely on patient records for diagnostic risk prediction, financial institutions assess creditworthiness and fraud using structured features, and scientific studies aggregate multi-sensor measurements to discover new insights. Yet despite this ubiquity, deep learning on tabular data has long lagged behind the breakthroughs achieved in domains such as natural language processing and computer vision.
Traditional approaches like gradient-boosted decision trees (e.g., XGBoost [1], LightGBM [2], CatBoost [3]) remain dominant because they reliably handle heterogeneous features, variable sample sizes, and small datasets—challenges that standard neural networks often struggle with. Deep models frequently underperform on tabular benchmarks due to the lack of spatial or temporal structure, making feature extraction less amenable to convolutional or sequential architectures. Moreover, tabular datasets often exhibit high heterogeneity—mixing numerical, categorical, and ordinal variables—and suffer from missing values and skewed distributions, which violate many of the inductive biases that make deep learning successful in other modalities. As a result, practitioners continue to favor tree ensembles and gradient boosting for their robustness, interpretability, and low data requirements.
Recently, the advent of tabular foundation models (TFMs) has begun to reshape this landscape. These models extend the “foundation model” paradigm—pretraining on large, diverse corpora followed by downstream adaptation—to structured data domains. Models such as TabPFN [4, 5], TabICL [6], OrionMSP [7], and OrionBiX [8] leverage large-scale pre-training on synthetic or massive tabular datasets to provide generic, out-of-the-box learning capabilities.
For example, TabPFN demonstrates strong few-shot classification performance on small to medium datasets without additional gradient updates, approximating Bayesian posterior inference in a single forward pass. Meanwhile, TabICL extends this paradigm to larger datasets, scaling in-context learning to hundreds of thousands of samples, while the Orion family introduces efficient multi-scale and biaxial attention mechanisms that enhance scalability and accuracy. These developments mark a significant step toward “general-purpose” tabular learners that can adapt rapidly to new datasets with minimal supervision.
However, despite their promise, adopting these models in real-world practice remains hampered by several frictions:
- Diverse preprocessing requirements: Each model demands its own data encoding, feature normalization, and missing-value strategy—requiring practitioners to build bespoke pipelines for each model family. For example, TabPFN expects numerically encoded categorical features consistent with its synthetic priors, whereas TabICL and Orion architectures rely on learned embeddings or set-transformer encoders for categorical attributes.
- Fragmented APIs and training protocols: Some models operate purely in zero-shot inference mode (zero fine-tuning), others support supervised fine-tuning (SFT) or parameter-efficient fine-tuning (PEFT), specifically Low-Rank Adaptation (LoRA; see Section 2 for details). Managing these disparate workflows is laborious and error-prone, particularly when comparing multiple model families under consistent experimental settings.
- Evaluation gaps in deployment-relevant metrics: While accuracy improvements are well documented, aspects such as calibration of probability estimates, fairness across subgroups, and resource-efficiency trade-offs are under-explored in a unified framework. This absence of standardization makes it difficult to assess whether performance gains translate to trustworthy or deployable behavior.
- Model selection complexity: With multiple models and tuning strategies available, users face non-trivial questions: Which model best suits a small vs. large dataset? What is the memory/latency trade-off? How do calibration and fairness behave under different tuning regimes? In practice, this uncertainty often discourages the adoption of TFMs despite their potential benefits.
To bridge these gaps, we introduce TabTune, a unified, scikit-learn-compatible toolkit that standardizes the full modelling workflow for tabular foundation models. TabTune offers:
- A single interface for multiple TFM families, handling model-specific preprocessing internally and exposing consistent fit–predict semantics.
- Support for a spectrum of adaptation strategies: zero-shot inference, meta-learning, full supervised fine-tuning (SFT), and parameter-efficient fine-tuning (PEFT). This design allows practitioners to switch between inference paradigms seamlessly using a unified API.
- Built-in diagnostics for calibration (Expected Calibration Error, Maximum Calibration Error, Brier score) and fairness (Statistical Parity Difference, Equalised Odds Difference, Equalised Opportunity Difference), enabling a holistic assessment of model trustworthiness and risk.
- A systematic benchmarking module across standard tabular suites (e.g., TALENT [9], OpenML-CC18 [10]) that evaluates accuracy, calibration, fairness, and resource efficiency in a unified ranking framework, facilitating reproducible and comparative studies of TFM performance.
With TabTune, practitioners can quickly experiment with multiple model/tuning configurations using consistent functions (e.g., .fit(), .predict(), .evaluate()), without rewriting preprocessing logic or training loops. Moreover, TabTune serves as an experimental bed for studying the interplay between learning paradigms—such as zero-shot inference versus parameter-efficient tuning—and their downstream effects on calibration, fairness, and computational efficiency. For detailed system architecture, see Section 2. Through comprehensive experiments, we demonstrate that TabTune not only simplifies workflows, but also provides new insights into the trade-off space of accuracy, calibration, fairness and efficiency across tabular foundation models.
In the remainder of the paper, Section 2 reviews prior work on tabular foundation models and adaptation techniques. Section 2 details the system design of TabTune, Section 6 describes our experimental setup and benchmark results, and Section 7 offers practical guidance on model selection, discusses limitations, and outlines future directions.
2 Related Work
2.1 Traditional Machine Learning and Deep Learning for Tabular Data
Tabular data—structured as records (rows) and features (columns)—is pervasive across applications such as healthcare, finance, industrial analytics, and scientific research. For decades, models based on gradient-boosted decision trees (GBDTs) such as XGBoost, LightGBM, and CatBoost have dominated supervised learning on tabular tasks. These methods reliably handle heterogeneous feature types, missing values, and small to medium sample sizes, while requiring only modest hyper-parameter tuning. Their robustness and simplicity have made them the de facto standard for tabular prediction tasks in both research and production settings.
In recent years, deep neural networks—such as feed-forward multilayer perceptrons, attention-based architectures, and hybrid tree–neural models—have been applied to tabular data [11, 12]. Despite significant progress, these models have often struggled to consistently outperform GBDTs in real-world benchmarks. This gap arises from several challenges: the heterogeneity of tabular data, limited dataset sizes, complex feature–target relationships, and the absence of large-scale pre-training strategies analogous to those that revolutionized vision and language modeling.
2.2 Tabular Foundation Models
A major paradigm shift has recently emerged with the advent of tabular foundation models (TFMs)—large pretrained architectures that aim to generalize across diverse tasks, often through in-context learning (ICL) or single forward-pass inference without task-specific gradient updates. In the context of TFMs, zero-shot inference refers to the "fit then predict" paradigm: during the fit phase, the model receives training samples as context (without gradient-based parameter updates), and during the predict phase, it performs in-context learning through forward passes alone to make predictions on test samples. Unlike traditional machine learning where "fit" implies gradient updates and training, in TFMs the fit step simply provides context samples to the pretrained model, enabling rapid adaptation without requiring training time.
TabPFN (Tabular Prior-data Fitted Network) represents one of the earliest and most influential TFMs. It employs a transformer architecture trained on vast collections of synthetic tabular datasets, effectively learning to approximate Bayesian inference across varying generative priors. This pre-training strategy enables TabPFN to achieve strong few-shot and zero-shot performance on small to medium datasets (typically up to ∼10,000 samples), offering competitive accuracy without explicit fine-tuning [4, 5].
Building on this foundation, TabICL extends the in-context learning paradigm to larger-scale tabular datasets by introducing a novel two-stage column-then-row attention mechanism. Through large-scale synthetic pre-training (up to ∼60K samples) and robust scaling to half a million samples at inference time, TabICL demonstrates that transformer-based ICL can challenge traditional tree ensembles even on large tabular domains [6].
Another direction, TabDPT, introduces denoising-based or self-supervised pre-training strategies that learn robust feature representations from both synthetic and real-world tables [13]. In parallel, other approaches explore the role of mixed synthetic priors, showing that a combination of causal, statistical, and randomized priors during pre-training can substantially improve downstream generalization and calibration performance across classification and regression tasks. Collectively, these developments illustrate that, with sufficient architectural bias and large-scale pre-training, transformer-based TFMs can achieve broad generalization on structured data—challenging long-held assumptions about the superiority of tree-based ensembles in tabular learning. Recent comprehensive surveys have catalogued the landscape of tabular foundation models [14, 15], highlighting their potential to transform tabular learning. Recent work has demonstrated that careful fine-tuning strategies can yield significant improvements for TFMs [16]. Meanwhile, researchers have argued that tabular foundation models should be a research priority [17], given their potential impact across domains.
OrionMSP [7] introduces a transformer architecture for tabular in-context learning that combines multi-scale sparse attention—capturing both local and global feature dependencies efficiently—with a Perceiver-style latent memory that enables safe bidirectional communication between training and test samples. It uses column-wise embeddings via Set Transformers to model feature distributions and a split-masked causal attention mechanism for proper ICL reasoning. The design achieves near-linear attention scaling while maintaining high accuracy across diverse datasets, rivaling or outperforming TabICL and TabPFN—especially on heterogeneous, high-dimensional, and imbalanced datasets—thus demonstrating robust, efficient, and generalizable tabular learning without gradient updates.
Similarly, OrionBiX [8] employs a biaxial attention mechanism for tabular in-context learning, enabling bidirectional context modeling across both rows and columns of tabular data. This dual-axis attention pattern allows the model to capture complex feature interactions and sample relationships simultaneously, providing a more comprehensive representation of tabular structure. The biaxial design facilitates effective information flow between training and test samples, enabling strong in-context learning performance across diverse tabular datasets while maintaining computational efficiency.
2.3 Representation Learning and Alternative Approaches
While transformer-based TFMs dominate recent work, alternative representation learning paradigms have been explored. Graph neural networks have been adapted for tabular data, modeling feature relationships through graph structures [18]. Extensions of foundation models to time series forecasting demonstrate their versatility; for instance, TabPFN-v2 has shown competitive performance on temporal tasks [19], suggesting that tabular foundation models may generalize beyond traditional classification settings.
2.4 Tabular ML Toolkits and Frameworks
Several frameworks have emerged to facilitate deep learning with tabular data, each addressing different aspects of the modeling pipeline. AutoGluon [20] is an AutoML framework that automates model selection and hyperparameter tuning for tabular data, employing neural architecture search and ensemble methods to achieve strong predictive performance with minimal manual configuration. PyTorch Tabular [21] provides a modular framework for deep learning with tabular data, offering reusable components for neural network architectures tailored to structured data. However, these frameworks primarily focus on training models from scratch or performing architecture search, rather than working with pretrained tabular foundation models.
In contrast, TabTune is the first unified framework specifically designed for tabular foundation models, bridging the gap between pretrained TFM architectures and practical deployment workflows. While existing toolkits excel at discovering or building models from scratch, TabTune addresses the unique challenges of working with pretrained TFMs: standardizing diverse preprocessing requirements, unifying adaptation strategies (zero-shot inference, meta-learning, supervised fine-tuning, and parameter-efficient fine-tuning), and providing built-in evaluation diagnostics for calibration and fairness. This specialization enables practitioners to leverage the powerful generalization capabilities of pretrained TFMs without the complexity of managing model-specific interfaces and workflows.
2.5 Adaptation Techniques: Meta-Learning, Fine-Tuning, and PEFT
Although inference-only TFMs exhibit strong generalization, many real-world applications benefit from adapting to target distributions. Three key adaptation paradigms have emerged.
Meta-learning (or episodic fine-tuning) uses support–query splits from training data to retain in-context generalization while improving task-specific performance [22]. This approach has proven effective for tabular foundation models such as TabICL, where episodic training enhances accuracy and supports few-shot adaptation to new distributions [6, 13].
Supervised fine-tuning (SFT) updates all model parameters on labeled data when sufficient resources are available [23]. In tabular domains, full fine-tuning often yields notable gains over inference-only use, especially on large datasets where models learn domain-specific patterns [6, 13]. However, it remains computationally and storage intensive, as every parameter must be updated per task.
Parameter-efficient fine-tuning (PEFT) methods, such as Low-Rank Adaptation (LoRA) [24], limit updates to low-dimensional subspaces, greatly reducing compute and memory costs while preserving performance. Surveys categorize PEFT into additive (adapters), selective (partial updates), and reparameterization-based (low-rank) approaches [25]. Empirical studies show that PEFT matches or surpasses full fine-tuning with far lower resource demands [26]. For tabular foundation models, PEFT enables efficient domain adaptation under tight resource budgets, supporting rapid experimentation and scalable deployment. Together, these paradigms bridge the gap between zero-shot inference and fully supervised modeling, promoting adaptable TFMs for diverse applications.
2.6 Calibration, Fairness, and Responsible Deployment
As tabular foundation models progress from research to deployment, challenges of trustworthiness, calibration, fairness, and robustness have become increasingly central.
Calibration reliability—the alignment between predicted probabilities and actual outcomes—is vital for high-stakes decision-making. Guo et al. [27] showed that modern neural networks often exhibit systematic miscalibration, motivating metrics such as Expected Calibration Error (ECE) and Maximum Calibration Error (MCE) to measure these gaps. For tabular foundation models, early results suggest that pretrained transformers yield better-calibrated confidence estimates than classical ensembles, especially in low-data settings where in-context learning supports more nuanced uncertainty estimation.
Fairness requires that models avoid systematic bias across demographic groups [28]. Fairness frameworks propose criteria such as equalized odds [29]—requiring equal true and false positive rates—and equal opportunity, focusing on true positive rate parity. [30] revealed a fundamental tension between perfect calibration and strict fairness, showing that these objectives can conflict. In-context learning setups may further amplify biases present in demonstration data. Mitigation strategies include group-balanced sampling, fair demonstration selection, and uncertainty-based data curation.
Robustness—the stability of model behavior under distributional shift, perturbations, and adversarial attacks—remains an open challenge. While tabular foundation models benefit from large-scale, heterogeneous pretraining, their behavior under shift and noise is not yet fully characterized. These considerations highlight the need for unified evaluation frameworks that jointly assess predictive performance, calibration, fairness, and robustness to ensure the responsible deployment of tabular foundation models.
3 System Design
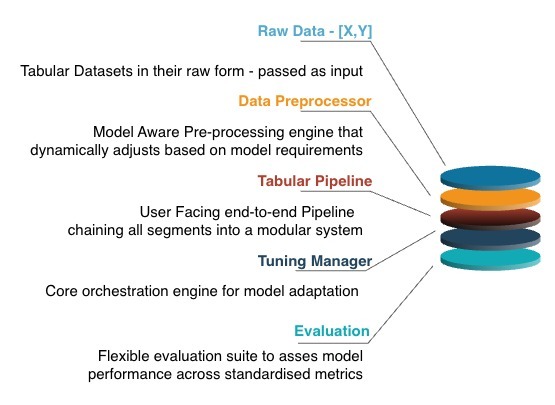
The design of TabTune emphasizes abstraction of the operational complexity associated with modern tabular foundation models (TFMs), while preserving flexibility for advanced adaptation, benchmarking, and experimentation. The framework adopts a strictly modular architecture in which preprocessing, tuning, and orchestration layers are decoupled yet interoperable, ensuring extensibility and transparency across research and production workflows (Figure 2).
3.1 Design Principles
Unified Interface. TabTune exposes a consistent, high-level API that provides unified access to all supported TFMs, including TabPFN, TabDPT, TabICL, Mitra, ContextTab, OrionMSP and OrionBiX . Through a shared syntax for model initialization, training, and evaluation, it eliminates the need for users to adapt to model-specific conventions or data representations, enabling seamless experimentation across architectures.
Model-Aware Automation. The framework automatically identifies the chosen model and configures preprocessing, hyperparameters, and adaptation procedures accordingly. Whether deploying a zero-shot TabPFN, performing episodic meta-learning with TabICL, or applying parameter-efficient LoRA fine-tuning, TabTune dynamically selects optimized defaults aligned with the model’s internal design and capacity. This automation reduces manual configuration overhead and ensures consistency across runs.
Unified Workflow Compatibility. All models in TabTune follow a consistent workflow based on standardized method calls such as fit(), predict(), and evaluate(). This design allows easy integration into broader machine learning pipelines and benchmarking frameworks, enabling reproducible and interpretable experimentation without requiring specialized wrappers or retraining scripts.
3.2 Modular Architecture
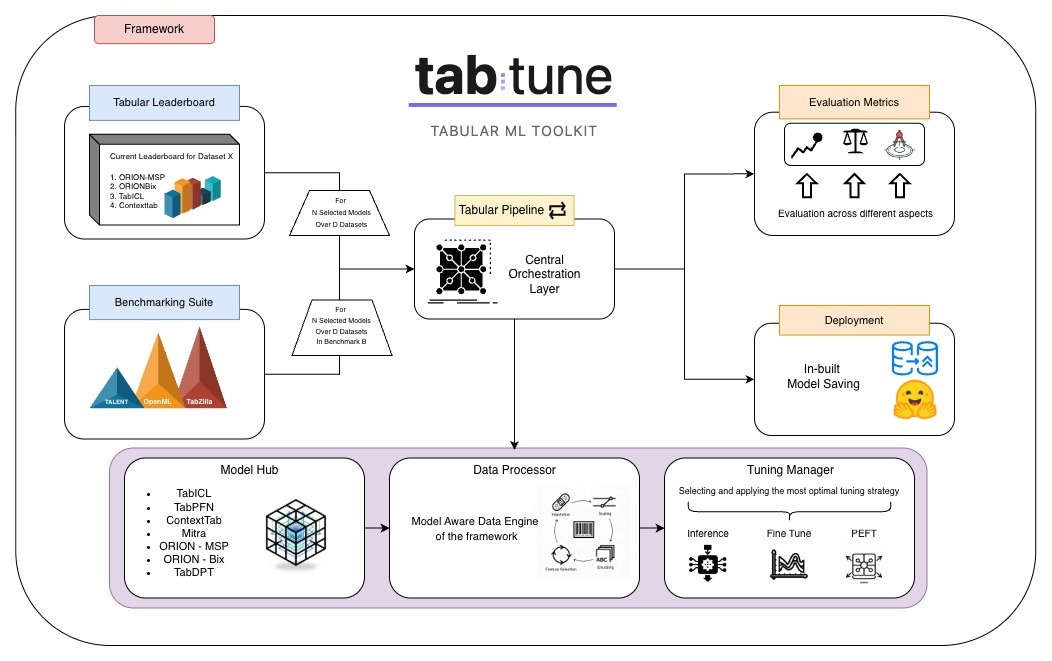
TabTune’s architecture is composed of four interdependent modules that collectively handle data processing, model adaptation, inference, and evaluation. These components are designed to remain logically independent yet harmonized through a unified orchestration layer.
- TabularPipeline module, which serves as the main user interface and orchestrator of the modeling workflow. It encapsulates the selected TFM, manages persistence through save() and load() utilities, and coordinates the complete pipeline—from preprocessing and fine-tuning to evaluation and model comparison.
- The DataProcessor component is responsible for handling model-specific preprocessing logic. Upon initialization, it dynamically loads specialized processors and performs imputation, normalization, encoding, and embedding generation as required.
- The TuningManager module constitutes the computational backbone of TabTune. It executes the selected adaptation strategy—ranging from zero-shot inference to supervised fine-tuning, meta-learning, and parameter-efficient fine-tuning (PEFT). The manager implements training routines in a unified format, abstracts gradient updates, and integrates lightweight adaptation methods such as LoRA to reduce computational and memory costs while maintaining model generalization. For meta-learning configurations, episodic training is supported through dynamic support–query sampling, preserving the in-context adaptability of transformer-based models.
- Complementing these components, the TabularLeaderboard module enables systematic evaluation and large-scale comparison of model variants. It automates training and evaluation over consistent data partitions and produces ranked summaries across metrics such as AUC, F1-score, and inference efficiency. This functionality transforms comparative model assessment into a reproducible and configurable experiment suite.
3.3 Supported Models
TabTune includes built-in support for seven prominent tabular foundation models, default tuning configurations, and aligned preprocessing pipelines. This design ensures that every model can be instantiated, fine-tuned, and evaluated with minimal configuration effort, while preserving model-specific fidelity.
Table 1:Tabular foundation models supported in TabTune. Paradigm indicates the learning approach—ICL, Prior-Fitted Network, Denoising Transformer, or Scalable ICL. Key Feature summarizes each model’s core architectural element (e.g., attention).
4 Implementation
This section describes how TabTune’s implementation is organized around three core components—the DataProcessor, TuningManager, and TabularPipeline—which together enable seamless preprocessing, adaptation, and inference through a standardized interface.
4.1 Model-Aware Preprocessing
The DataProcessor dynamically loads model-specific routines to format data correctly with minimal user setup. For TabPFN, features are mapped to numerical or integer-encoded tensors to align with its synthetic priors. ContextTab [31] adds semantic vectors for column names and categorical values. TabICL and Mitra apply normalization and model-tailored transformations. For OrionMSP [7] and OrionBiX [8], preprocessing is distribution- and hierarchy-aware: columns are embedded with Set Transformer-based induced set attention on train rows only, numerical features are standardized and categorical values embedded, multi-scale row inputs and block-sparse attention masks are constructed, Perceiver-style memory is written by train rows and read by all rows, and label injection uses split-masked attention to prevent test-to-train leakage. Compared to TabICL [6], Orion adds distribution-aware column embeddings and multi-scale sparsity for scalable, ICL-safe processing. Together, these routines ensure each TFM receives inputs in its expected schema.
4.2 Flexible Tuning Strategies
The TuningManager module governs model adaptation and optimization, executing the selected strategy specified during pipeline initialization. It provides a unified training controller that supports four complementary regimes—inference, supervised fine-tuning, meta-learning, and parameter-efficient fine-tuning (PEFT)—under a common abstraction.
- Zero-shot inference, TabTune performs zero-shot prediction using pretrained weights, exploiting the generalization capacity of models such as TabPFN for small datasets without parameter updates.
- Supervised fine-tuning extends this by optimizing all model parameters through gradient-based learning on labeled data, allowing users to specify training details (e.g., number of epochs or learning rate) via the configuration dictionary. For in-context learning models such as TabICL and Mitra, batches are split into pseudo-episodes where the first half serves as support context and the second half as query targets, maintaining the episodic structure required by the model architecture.
- Meta-learning fine-tuning introduces episodic adaptation, where models are trained on dynamically sampled support–query pairs to maintain in-context generalization while improving task-specific accuracy. Each episode randomly samples disjoint support and query sets from the training data, with class labels normalized to contiguous indices within each episode to ensure compatibility with fixed-size classification heads. This approach is particularly effective for transformer-based architectures like TabICL and TabDPT that rely on in-context reasoning.
- Parameter-Efficient fine-tuning (PEFT)—implemented via Low-Rank Adaptation (LoRA)—reduces computational cost by updating only small low-rank matrices within attention layers. LoRA is configured with rank r=8 and scaling factor α=16, injecting trainable adapters into attention projection layers. When LoRA application fails due to architectural constraints, the framework automatically falls back to standard fine-tuning. This technique significantly lowers memory requirements while preserving performance and is supported for both supervised and meta-learning modes.
4.2.1 PEFT Implementation Details:
The fine-tuning framework determines target layers for parameter-efficient adaptation automatically based on model architecture. Updates are typically restricted to attention projections and core transformer components, while dynamic or task-specific heads are excluded. If no predefined targets are detected, adapters are applied to all eligible linear layers. When adapter injection is incompatible with the underlying architecture, the system reverts to standard full-parameter fine-tuning.
4.2.2 Episodic Training Mechanics:
For meta-learning adaptation, episodes are formed by sampling disjoint support and query sets from the training data. Each episode contains S labeled support examples and Q query examples used for evaluation. The model is conditioned on the support labels and optimized to predict the query labels within each episode. To ensure compatibility with fixed-size classification heads, class labels are remapped to contiguous indices {0,1,…,K−1} according to the support set. Episodes in which query samples include unseen classes are excluded to preserve consistency.
4.2.3 Data Sampling Strategies
The framework incorporates optional resampling techniques to address label imbalance and promote a well-diversified dataset for model context, while remaining independent of the core modeling workflow. Resampling is applied exclusively to the training split to avoid any data leakage into the validation or test sets.
Supported methods : The available options include: smote (Synthetic Minority Over-sampling Technique), random_over (random oversampling), random_under (random undersampling), tomek (Tomek links removal), kmeans (cluster centroids undersampling), and knn (neighborhood cleaning rule). These methods enable flexible control over class balance and support reproducible experimentation across diverse tabular datasets.
4.3 Evaluation Utilities
TabTune provides comprehensive evaluation capabilities across performance, calibration, and fairness. Beyond these standard metrics, TabTune also includes built-in utilities for assessing model calibration and fairness—critical dimensions for responsible deployment in high-stakes applications.
- The evaluate() method computes standard classification metrics including accuracy, precision, recall, F1-score, and AUC-ROC, enabling rapid assessment of predictive performance across models and tuning strategies (Listing LABEL:lst:performance_eval).
- The evaluate_calibration() method computes Expected Calibration Error (ECE), Maximum Calibration Error (MCE), and Brier score to quantify the reliability of predicted probabilities. These metrics reveal whether a model’s confidence estimates align with actual prediction accuracy, essential for decision-making systems in healthcare, finance, and autonomous applications.
- The evaluate_fairness() method assesses demographic parity and equalized odds across sensitive attributes, measuring whether predictions exhibit systematic bias across subgroups. Users specify sensitive features (e.g., gender, race, age) and receive Statistical Parity Difference (SPD), Equalised Odds Difference (EOD), and more, enabling practitioners to identify and mitigate algorithmic bias before deployment.
4.4 Pipeline Abstraction and Workflow
The TabularPipeline serves as the primary orchestration layer for integrating the preprocessing and tuning components. It manages the end-to-end flow—data ingestion, preprocessing, adaptation, and prediction—through a unified API that abstracts low-level operations.
The following demonstrates the core workflow for model initialization, training, and inference. The pipeline detects the model type, loads the corresponding preprocessing backend, and delegates adaptation to the TuningManager. In this example, the user specifies only the model and adaptation mode. TabTune internally triggers three automated steps: (1) the DataProcessor formats the dataset to match the model’s expected schema, (2) the TuningManager selects and executes the correct adaptation strategy, and (3) the TabularPipeline aggregates predictions and handles evaluation. This design illustrates how the framework abstracts operational complexity behind a minimal interface, enabling quick prototyping and reproducible experimentation.
from tabtune import TabularPipeline
# Initialize the pipeline with model configuration
pipeline = TabularPipeline(model_name="OrionMSP",tuning_strategy="inference")
#Train and predict
pipeline.fit(X_train, y_train)
predictions = pipeline.predict(X_test)4.5 Benchmarking with TabularLeaderboard
To facilitate large-scale model comparison and reproducibility, TabTune includes the TabularLeaderboard module. This component automates benchmarking across multiple TFMs and adaptation modes under consistent data splits, producing ranked summaries based on selected metrics such as AUC, F1-score, and training efficiency. Listing LABEL:lst:leaderboard shows a representative use case where several models and tuning regimes are benchmarked on the same dataset. Each configuration defines its own adaptation strategy and hyperparameters, while TabTune ensures standardized preprocessing and evaluation across all runs.The leaderboard system illustrates the high-level orchestration capabilities of TabTune’s architecture. Internally, it constructs multiple TabularPipeline instances, each managing its respective preprocessing and tuning configuration, and executes them in parallel under uniform conditions. The results are aggregated and ranked automatically, providing a reproducible, interpretable, and scalable benchmarking framework for evaluating tabular foundation models. Following demonstrates both evaluation modes, which can be applied to any TabTune model after training.
from tabtune import TabularLeaderboard
# Initialize leaderboard
leaderboard = TabularLeaderboard(X_train, X_test, y_train, y_test)
# Add model configurations
leaderboard.add_model(model_name=’TabPFN’,tuning_strategy=’inference’)
leaderboard.add_model(model_name=’OrionBix’,tuning_strategy=’finetune’,
tuning_params={’epochs’: 5})
leaderboard.add_model(model_name=’OrionMSP’,tuning_strategy=’inference’)
# Execute and rank models
results = leaderboard.run(rank_by=’roc_auc_score’)
5 Usage Scenarios
This section demonstrates TabTune’s capabilities through several scenarios, showcasing the framework’s functionality. These examples provide hands-on illustrations of the system components described in Section 4.
5.1 Basic Usage and Multi-Model Switching
TabTune’s unified API allows seamless experimentation across foundation models with identical workflows. Switching between the seven supported models requires only a parameter change—no need to learn new APIs or preprocessing steps. This consistency enables rapid prototyping, performance comparison, and deployment without rewriting data or training code. Model persistence ensures reproducibility and version control.
1from tabtune import TabularPipeline
# Example 1: TabPFN Model
pipeline_pfn = TabularPipeline(model_name="TabPFN",tuning_strategy="inference")
pipeline_pfn.fit(X_train, y_train)
predictions_pfn = pipeline_pfn.predict(X_test)
# Example 2: OrionMSP Model with semantic features
pipeline_OrionMSP = TabularPipeline(model_name="OrionMSP",tuning_strategy="inference")
pipeline_OrionMSP.fit(X_train, y_train)
predictions_OrionMSP = pipeline_OrionMSP.predict(X_test)5.2 Model Comparison and Results Analysis
This scenario showcases systematic benchmarking of multiple models and tuning strategies with detailed performance insights. The leaderboard automates cross-validation, metric computation, and ranking across all configurations. Results can be exported as structured DataFrames for analysis, visualization, or automated model selection—enabling data-driven decisions on the best model–tuning combination for a given dataset and deployment setting.
from tabtune import TabularLeaderboard
leaderboard = TabularLeaderboard(X_train, X_test,y_train, y_test)
# Add multiple model configurations
leaderboard.add_model(model_name=’TabPFN’,tuning_strategy=’inference’)
leaderboard.add_model(model_name=’TabICL’,tuning_strategy=’finetune’,tuning_params={’epochs’:5})
leaderboard.add_model(model_name=’OrionMSP’,tuning_strategy=’inference’)
# Run comparison and get detailed results
results = leaderboard.run(rank_by=’roc_auc_score’)5.3 Fine-Tuning Demonstration
This scenario demonstrates the different fine-tuning strategies available in TabTune. Each approach offers distinct trade-offs between performance, and generalization capability.
5.3.1 Supervised Fine-Tuning (SFT)
Supervised fine-tuning optimizes all model parameters using standard mini-batch gradient descent. This approach typically achieves the highest accuracy when sufficient training data is available.
from tabtune import TabularPipeline
# Full supervised fine-tuning
sft_pipeline = TabularPipeline(
model_name=’OrionMSP’,
tuning_strategy=’finetune’,
tuning_params={’finetune_mode’: ’sft’,’epochs’: 5,’learning_rate’: 1e-4}
sft_pipeline.fit(X_train, y_train)
sft_metrics = sft_pipeline.evaluate(X_test, y_test)5.3.2 Meta-Learning Fine-Tuning
Meta-learning fine-tuning uses episodic training, where the model learns to adapt from support sets to query sets within each episode. This approach preserves in-context learning capabilities while improving task-specific performance.
from tabtune import TabularPipeline
# Meta-learning fine-tuning
meta_pipeline = TabularPipeline(
model_name=’OrionMSP’,
tuning_strategy=’finetune’,
tuning_params={
’finetune_mode’: ’meta-learning’,
’epochs’: 3, ’learning_rate’: 5e-5, ’support_size’: 48, ’query_size’: 32
}
)
meta_pipeline.fit(X_train, y_train)
meta_metrics = meta_pipeline.evaluate(X_test, y_test)5.3.3 Parameter-Efficient Fine-Tuning with SFT (PEFT SFT)
PEFT SFT combines LoRA adapters with supervised fine-tuning, achieving comparable performance to full fine-tuning while reducing memory usage by 60–80%.
from tabtune import TabularPipeline
# PEFT with supervised fine-tuning
peft_sft_pipeline = TabularPipeline(
model_name=’TabICL’,
tuning_strategy=’peft’,
tuning_params={
’finetune_mode’: ’sft’, ’epochs’: 5,
’peft_config’: {’r’: 8,’lora_alpha’: 16,’lora_dropout’: 0.05}
}
)
peft_sft_pipeline.fit(X_train, y_train)
peft_sft_metrics = peft_sft_pipeline.evaluate(X_test, y_test)5.3.4 Parameter-Efficient Fine-Tuning with Meta-Learning (PEFT Meta-Learning)
PEFT meta-learning combines LoRA adapters with episodic training, offering the benefits of both parameter efficiency and in-context generalization.
from tabtune import TabularPipeline
# PEFT with meta-learning
peft_meta_pipeline = TabularPipeline(
model_name=’TabICL’,
tuning_strategy=’peft’,
tuning_params={’finetune_mode’: ’meta-learning’, ’epochs’: 3,
’support_size’: 48, ’query_size’: 32,
’peft_config’: {’r’: 8, ’lora_alpha’: 16, ’lora_dropout’: 0.05}}
)
peft_meta_pipeline.fit(X_train, y_train)
peft_meta_metrics = peft_meta_pipeline.evaluate(X_test, y_test)5.4 Comprehensive Model Evaluation
This scenario demonstrates TabTune’s built-in evaluation utilities across three dimensions: standard performance metrics, probability calibration, and fairness analysis.
5.4.1 Performance Metrics Evaluation
Standard classification metrics provide the foundation for model assessment. TabTune’s evaluate() method computes accuracy, precision, recall, F1-score, and AUC-ROC in a unified call.
from tabtune import TabularPipeline
pipeline = TabularPipeline(model_name=’TabICL’,tuning_strategy=’finetune’)
pipeline.fit(X_train, y_train)
# Comprehensive performance evaluation
performance = pipeline.evaluate(X_test, y_test)
print(f"Accuracy: {performance[’accuracy’]:.4f}")
print(f"AUC-ROC: {performance[’roc_auc_score’]:.4f}")
print(f"F1-Score: {performance[’f1_score’]:.4f}")5.4.2 Calibration Evaluation
Calibration assessment quantifies the reliability of predicted probabilities—essential for deployment in decision-critical applications. The evaluate_calibration() method returns ECE, MCE, and Brier score metrics.
# Assess probability calibration quality
calibration_metrics = pipeline.evaluate_calibration(X_test, y_test, n_bins=15)
print(f"Expected Calibration Error: {calibration_metrics[’expected_calibration_error’]:.4f}")
print(f"Maximum Calibration Error: {calibration_metrics[’maximum_calibration_error’]:.4f}")
print(f"Brier Score: {calibration_metrics[’brier_score_loss’]:.4f}")5.4.3 Fairness Evaluation
Fairness analysis detects systematic bias across demographic groups, enabling responsible model deployment. Users specify sensitive attributes, and TabTune computes demographic parity and equalized odds metrics.
# Evaluate fairness across sensitive attributes
fairness_metrics = pipeline.evaluate_fairness(X_test,y_test,sensitive_features=gender_column)
print(f"Statistical Parity Difference: {fairness_metrics[’statistical_parity_difference’]:.4f}")
print(f"Equalized Odds Difference: {fairness_metrics[’equalized_odds_difference’]:.4f}")5.5 Model Persistence and Checkpointing
TabTune supports end-to-end pipeline persistence and checkpointing for reproducible experiments and deployment.
from tabtune import TabularPipeline
# Train and save a fine-tuned model
pipeline = TabularPipeline( model_name=’TabICL’,tuning_strategy=’finetune’,tuning_params={’epochs’: 5}
)
pipeline.fit(X_train, y_train)
performance = pipeline.evaluate(X_test, y_test)
print(performance)
# Save the entire pipeline (preprocessor + model + config)
pipeline.save(’my_model.joblib’)
# Load and use for predictions
loaded_pipeline = TabularPipeline.load(’my_model.joblib’)
performance = loaded_pipeline.evaluate(X_test, y_test)
print(performance)6 Experimental Results
We conduct a comprehensive evaluation of TabTune across multiple dimensions: predictive performance, probability calibration, fairness, and scalability. This section presents our experimental design and detailed results across diverse tabular learning scenarios.
6.1 Experimental Design
6.1.1 Benchmark Suites and Datasets.
Our experiments encompass three well-established benchmark suites—TALENT [9] (181 automatically discovered datasets), OpenML-CC18 [10] (72 curated datasets), and TabZilla [32] (36 heterogeneous tasks)—facilitating a systematic comparison across a broad spectrum of tabular learning settings. We further conduct domain-specific evaluations in high-impact areas such as medical and financial domains to assess the practical applicability of the methods. All experiments adhere to the standardized dataset splits defined by each benchmark, ensuring both reproducibility and fairness in comparison.
To maintain consistency and fairness across model families, benchmark results are computed only on the common subset of datasets available for all evaluated models within each benchmark suite. This unified evaluation protocol ensures that performance rankings and metrics reflect genuine methodological differences rather than disparities in dataset coverage. In total, our evaluations span 155/181 datasets for TALENT, 27/36 datasets for TabZilla, and 63/72 datasets for OpenML-CC18. Some datasets were excluded due to out-of-memory (OOM) errors even on H200 GPUs or CUDA-related issues, particularly affecting TabPFN-based models.
It is important to clarify how mean rank values are derived. Within each benchmark suite, models are ranked by accuracy on every dataset (lower rank = better performance), and these per-dataset ranks are averaged to obtain the overall mean rank. Thus, a lower mean rank indicates stronger and more consistent performance across datasets, rather than the highest score on any single task. While absolute metrics (accuracy, F1) reflect peak task-level performance, mean rank provides a normalized measure of cross-dataset generalization consistency.
Detailed dataset statistics are provided in Appendix 11.
6.1.2 Models and Adaptation Strategies.
We evaluate seven recent tabular foundation models—TabPFN, TabICL, OrionMSP, OrionBiX, Mitra, ContextTab, and TabDPT—under multiple adaptation paradigms, including zero-shot inference, meta-learning fine-tuning, supervised fine-tuning, parameter-efficient supervised fine-tuning, and parameter-efficient meta-learning. In addition, we include established traditional baselines using autogloun [20] such as XGBoost, LightGBM, CatBoost, and Random Forest as strong reference models for comparison.
6.1.3 Hardware Configuration.
Experiments are executed on NVIDIA L40S GPUs, with H200 GPUs used for memory-intensive cases. This infrastructure ensures consistent execution across all experiments while handling the computational demands of large transformer-based models.
6.1.4 Evaluation Metrics.
Our assessment covers four complementary dimensions:
Performance:
Classification Accuracy (ACC), AUC-ROC, and weighted F1-score (F1) quantify predictive capability across standard benchmark datasets (TALENT, OpenML-CC18, TabZilla) covering diverse dataset characteristics including small and large sample sizes, narrow and wide feature spaces, and balanced and imbalanced class distributions.
Scalability:
Analysis of performance variation across dataset sizes, feature dimensionality, and class imbalance provides practical guidance for model selection. This analysis uses the same benchmark datasets as performance evaluation, aggregated and summarized across these dimensions to reveal scalability patterns.
Calibration:
We evaluate how fine-tuning impacts calibration metrics across different models and adaptation strategies, measuring the alignment between predicted probabilities and actual outcomes, which is critical for decision-making systems. Our evaluation uses three standard metrics:
- Expected Calibration Error (ECE), which measures the average deviation between predicted confidence and observed accuracy across binned predictions;
- Maximum Calibration Error (MCE), which captures the worst-case calibration gap, identifying regions of systematic miscalibration; and
- Brier score, which quantifies both calibration and refinement by penalizing squared deviations between predicted probabilities and binary outcomes.
Fairness:
We assess equitable treatment across demographic subgroups using established fairness-oriented datasets with sensitive attributes (gender, age, race, income group). We measure three complementary fairness criteria that capture different notions of equitable treatment:
- Statistical Parity Difference (SPD) quantifies the absolute difference in positive prediction rates across groups, testing whether the model provides equal opportunity independent of sensitive attributes. A model satisfies demographic parity when SPD approaches zero, indicating that positive predictions are distributed proportionally across demographic groups.
- Equalized Odds Difference (EOD) measures disparities in both true positive and false positive rates across groups, ensuring consistent error profiles across subgroups. This criterion is more stringent than statistical parity, requiring not only proportional positive predictions but also equal accuracy within each group.
- Equalized Opportunity Difference (EOpD) focuses specifically on true positive rate parity, ensuring that qualified individuals receive equal treatment regardless of group membership. This metric is particularly relevant in settings where false negatives have severe consequences, such as loan approvals or hiring decisions.
6.1.5 Analysis Focus :
A central goal of our evaluation is to analyze how different adaptation strategies—zero-shot inference, meta-learning fine-tuning, and supervised fine-tuning—affect model behavior across multiple dimensions. We examine whether fine-tuning improves performance, influences calibration, and impacts fairness across domains. This comparative analysis offers practical guidance on selecting appropriate adaptation strategies for tabular foundation models in different application contexts.
6.2 Performance Evaluation
6.2.1 Overall Leaderboards
Table 3 presents comprehensive results across the TALENT, OpenML-CC18, and TabZilla benchmark suites, reporting mean rank, classification accuracy (ACC), and weighted F1-score (F1) for each model and adaptation strategy. The aggregated findings reveal clear and consistent trends in how adaptation mechanisms influence predictive performance and cross-dataset generalization.
Baselines and Zero-Shot Inference.
Classical Machine Learning methods remain strong reference baselines, attaining mean accuracies between 0.833 and 0.861 with aggregated ranks around 6.0. In contrast, pretrained tabular foundation models (TFMs) exhibit markedly stronger generalization even without task-specific training. Among these, OrionMSP achieves the best overall zero-shot rank of 3.58, reaching (ACC = 0.8461/F1 = 0.8360) on TALENT, (0.8722/0.8676) on OpenML-CC18, and (0.8821/0.8786) on TabZilla. TabPFN follows closely (overall rank - 4.61) with (ACC = 0.8514/F1 = 0.8412) on TALENT and up to (0.8752/0.8716) on TabZilla. TabDPT (Rank - 5.42) attains (ACC = 0.8408 / F1 = 0.8318) on TALENT and (0.8814/0.8775) on TabZilla, while Mitra (Rank - 11.77, ACC < 0.40) and ContextTab (Rank - 9.70) perform substantially worse. Overall, zero-shot TFMs exceed traditional machine learning models by roughly 2–4 percentage points in accuracy and three to four rank positions, demonstrating the strength of pretrained priors.
Meta-Learning Fine-Tuning.
Episodic meta-learning substantially improves both accuracy and rank stability relative to zero-shot inference. OrionMSP attains the lowest aggregate rank of 2.26, achieving (ACC=0.8401/F1=0.8310) on TALENT, 0.8548/0.8516 on OpenML-CC18, and (0.8735/0.8672) on TabZilla. TabPFN ranks 2.42 overall with accuracies of (0.8517/0.8414) on TALENT, (0.8842/0.8784) on OpenML-CC18, and (0.8663/0.8603) on TabZilla. TabDPT (rank 3.95) maintains consistent performance near (0.83/0.82). By contrast, architectures such as TabICL and OrionBiX exhibit instability on TabZilla, where TabICL’s F1 drops to 0.6845. These results indicate that meta-learning offers the most balanced compromise between generalization and task-specific adaptation.
Supervised Fine-Tuning (SFT).
Full parameter fine-tuning yields divergent outcomes across architectures. TabPFN benefits most, achieving the best overall rank (1.97) and maintaining high accuracy across all benchmarks (ACC = 0.8459–0.8697, F1 = 0.8350–0.8617). TabDPT ranks 2.79 overall and performs particularly well on TabZilla (rank 1.81), with (ACC = 0.8337, F1 = 0.8260). OrionMSP remains competitive (rank 2.88) with (ACC ≈ 0.79, F1 ≈ 0.76), whereas TabICL and OrionBiX suffer severe degradation—TabICL’s accuracy on TabZilla falls from 0.873 to 0.567 and F1 from 0.870 to 0.473 —indicating overfitting and loss of pretrained priors. These findings suggest that SFT is advantageous for Bayesian or probabilistic architectures such as TabPFN.
Parameter-Efficient Fine-Tuning (PEFT).
PEFT achieves near-SFT accuracy with significantly reduced computational overhead. In the meta-learning configuration, OrionMSP attains the best overall rank (2.21), recording (ACC = 0.7879/F1 = 0.7728) on TALENT, (0.8566/0.8453) on OpenML-CC18, and (0.8594/0.8581) on TabZilla. TabDPT follows closely (rank 2.28) with (0.8002/0.7910) on TALENT and (0.8600/0.8539) on OpenML-CC18. Under the supervised PEFT variant, TabDPT achieves the overall best rank (1.91) with (ACC ≈ 0.85 and F1 ≈ 0.84), while OrionMSP (rank 2.01) attains (0.821 / 0.807) on TabZilla. These results show that PEFT retains roughly 95% of full-fine-tuning accuracy while substantially lowering resource demands.
Discussion.
Across all adaptation regimes, TFMs consistently outperform traditional baselines by 2–4 percentage points in accuracy and approximately four rank positions.
TabPFN proves most resilient, achieving the top overall rank under SFT, whereas OrionMSP demonstrates superior cross-dataset generalization in meta-learning. TabDPT delivers near-optimal performance under PEFT, offering the most favorable efficiency–accuracy balance.
Conversely, models such as TabICL and OrionBiX are highly sensitive to full parameter updates and prone to overfitting. Collectively, these observations establish that careful alignment between model architecture and adaptation strategy is critical for maximizing the performance of tabular foundation models.
Key Takeaways:
- Overall leaderboard: Considering scores across all benchmark suites, the strongest overall performers are TabPFN and OrionMSP. TabPFN achieves the highest overall results, with mean accuracies between 0.85–0.88 and weighted F1 scores of 0.84–0.88, demonstrating exceptional cross-benchmark consistency. OrionMSP follows closely, reaching ACC ≈ 0.84–0.88 and F1 ≈ 0.83–0.88, and exhibits particularly strong generalization on OpenML-CC18 and TabZilla. Collectively, these Tabular Foundation Models (TFMs) surpass classical machine learning baselines by approximately 2–4 %, underscoring the advantage of pretrained tabular representations for cross-dataset generalization.
- Zero-shot performance: TabPFN and OrionMSP are the strongest zero-shot models, achieving ACC≈0.85–0.88 and F1≈0.84–0.88. OrionMSP attains peak accuracy on OpenML-CC18 and TabZilla, while TabPFN leads on TALENT and remains stable across all suites.
- Meta-learning benefits: Meta-learning fine-tuning consistently improves both accuracy and stability. OrionMSP achieves the best meta-learning results overall (ACC≈0.84–0.87, F1≈0.83–0.87), with TabPFN performing comparably and showing particularly strong results on OpenML-CC18.
- SFT trade-offs: Full supervised fine-tuning benefits probabilistic architectures such as TabPFN, which achieves the highest accuracies (ACC≈0.85–0.87, F1≈0.83–0.86) across all benchmarks. In contrast, models such as TabICL and OrionBiX exhibit severe degradation under SFT, reflecting overfitting and loss of pretrained priors.
- PEFT performance: Parameter-efficient fine-tuning attains near–full-finetuning accuracy. TabDPT achieves top results (ACC≈0.85, F1≈0.84) and maintains strong stability across benchmarks, while OrionMSP delivers competitive results (ACC≈0.82–0.86, F1≈0.80–0.85) with cross-dataset generalization.
6.2.2 Scalability Analysis
We analyze how model performance varies with dataset size, feature dimensionality, and class imbalance to inform model selection under different data regimes. This scalability analysis highlights which models and fine-tuning strategies perform best across varying data constraints.
Based on Dataset Size
Table 4 shows how fine-tuning influences performance across dataset scales.
- On small datasets (<1K samples), TabDPT achieves the highest zero-shot accuracy (ACC=0.8333, F1=0.8271), marginally ahead of TabPFN under meta-learning (0.8336/0.8256). OrionMSP (PEFT–Meta, 0.8275/0.8213) follows closely, confirming that transformer backbones still generalize well under constrained data. Fine-tuning TabICL or OrionBiX on small datasets causes sharp degradation (ACC drops >15%), revealing overfitting risk.
- For medium-sized datasets (1K–10K), TabPFN in meta-learning configuration leads (ACC=0.8638, F1=0.8548), followed by its SFT variant (0.8580/0.8485); both outperform all classical baselines
- On large-scale datasets (>10K), tree-based ensembles remain strong—XGBoost reaches (0.8969/0.8920)—but transformer TFMs scale competitively, with OrionMSP zero-shot (0.8843/0.8768) and TabDPT zero-shot (0.8831/0.8765) ranking second and third. Across all sizes, Mitra and ContextTab consistently underperform (ACC <0.65), reflecting limited scalability.
Based on Dataset Width
Table 5 reveals that feature dimensionality strongly shapes model behaviour.
- For narrow datasets (<10 features), performance converges across models: OrionMSP zero-shot (0.8394/0.8314) slightly leads, followed by TabDPT and TabPFN, while classical baselines remain competitive.
- On medium-width data (10–100 features), TabPFN dominates under both zero-shot (0.8676/0.8589) and meta-learning (0.8683/0.8579), outperforming all baselines and transformer variants.
- The advantage of TFMs becomes most pronounced on wide feature spaces (>100 features): TabPFN achieves exceptional results under SFT (ACC=0.9346, F1=0.9335) and meta-learning (0.9172/0.9533), far exceeding other models. TabICL and OrionBiX degrade when fully fine-tuned, confirming that dense feature spaces accentuate overfitting. Traditional models (CatBoost, XGBoost) remain competitive but trail by 2–3 %.
Based on Class Imbalance
Table 6 compares balanced (≥0.6) and imbalanced (<0.6) scenarios.
- Under balanced conditions, TabPFN (SFT) achieves the best rank (1.96) with ACC=0.8336, F1=0.8267, followed by OrionMSP (Meta Learning, rank 2.27).
- When class ratios become highly skewed, meta-learning fine-tuning provides the greatest stability: OrionMSP achieves rank 2.16 (ACC=0.8735, F1=0.8636), with TabPFN close behind (rank=2.50, ACC=0.8784, F1=0.8664). These results confirm that episodic adaptation enhances calibration and minority-class reliability, while tree-based models lose 3–5% in accuracy under severe imbalance.
Discussion.
Scalability analysis underscores that TabPFN, OrionMSP, and TabDPT each occupy distinct strengths. TabPFN excels on small, medium, and high-dimensional data where Bayesian priors and strong supervision prevail; OrionMSP scales best with large datasets and imbalanced distributions due to meta-learning robustness; and TabDPT sustains near-top performance across all settings with minimal computational overhead. Classical baselines remain reliable but consistently trail the best TFMs by 2–4% in accuracy.
Key Takeaways:
- Dataset size: Small datasets favor TabDPT (zero-shot) and TabPFN (Meta Learning); medium datasets favor TabPFN (meta & SFT); large datasets see XGBoost slightly leading, with OrionMSP and TabDPT close behind.
- Feature dimensionality: Wide datasets (>100 features) favor TabPFN (SFT, ACC 0.92, F1 0.92), confirming its strength for high-dimensional problems; medium-width data favor TabPFN (Meta Learning), while narrow data show minimal gaps between TFMs and baselines.
- Class imbalance: Meta-learning fine-tuning yields the best robustness under imbalance, with OrionMSP (Rank-2.16, ACC = 0.8735, F1 = 0.8636) outperforming other TFMs; TabPFN (rank 2.50) remains second-best.
- Overall trend: TFMs scale smoothly with data size, width, and balance, maintaining >2–4% advantage and >3 rank improvement over traditional baselines.
6.2.3 Domain-Specific Analysis
To assess real-world applicability beyond general scalability patterns, we evaluate model performance across high-stakes domains including Medical and Finance (Table 7). Within domain-specific suites, different fine-tuning strategies yield distinct advantages depending on the domain.
Medical Domain Performance.
On medical datasets, TabPFN with supervised fine-tuning (SFT) achieves the best overall results (Rank = 1.86, ACC = 0.8094, F1 = 0.7958), followed by its meta-learning variant (Rank = 2.28, ACC = 0.8133, F1 = 0.8000). OrionMSP performs strongly in zero-shot (ACC = 0.8045, F1 = 0.7916) and meta-learning settings (Rank = 2.20, ACC = 0.7744, F1 = 0.7645), but exhibits minor degradation under full SFT. TabDPT (PEFT–SFT) also performs competitively (Rank = 1.96, ACC = 0.7680, F1 = 0.7531), achieving near-optimal results with reduced fine-tuning cost. In contrast, transformer-heavy models such as TabICL and OrionBiX lose up to 7–10 % accuracy under SFT, confirming overfitting risk in small, noisy clinical datasets. Traditional baselines (XGBoost, LightGBM) remain competitive (ACC ≈ 0.79–0.80) but trail the best TFMs by 2–3 . Overall, the medical results demonstrate that Bayesian and meta-learning TFMs generalize more reliably under limited data and high noise.
Finance Domain Performance.
Financial datasets are typically larger and more imbalanced, amplifying the value of episodic and parameter-efficient adaptation. OrionMSP under meta-learning attains the best overall rank (2.26) and strong accuracy (ACC = 0.8209, F1 = 0.8089), narrowly surpassing TabPFN (meta, Rank = 3.00, ACC = 0.8220, F1 = 0.8056) and its SFT counterpart (Rank = 2.00, ACC = 0.8222, F1 = 0.8058). TabDPT (PEFT–SFT) maintains competitive accuracy (Rank = 2.82, ACC = 0.7782, F1 = 0.7543), while OrionMSP (PEFT–SFT) achieves the strongest overall efficiency–accuracy balance (Rank = 1.93, ACC = 0.7854, F1 = 0.7272). Transformer models such as TabICL degrade sharply under SFT (ACC drop > 12 %), whereas classical baselines remain robust (ACC ≈ 0.81) but underperform in F1 due to poor minority calibration. The finance domain thus emphasizes meta-learning as the most stable strategy for large-scale, imbalanced tabular data.
Discussion.
Across both domains, pretrained TFMs consistently outperform traditional baselines when appropriate fine-tuning strategies are used. TabPFN achieves the best reliability and calibration on small, noisy medical datasets, whereas OrionMSP dominates in large, high-imbalance financial contexts. TabDPT maintains strong performance in both settings through efficient PEFT adaptation, confirming that resource-efficient methods can match full SFT accuracy within 2 %. These trends highlight the need for strategy–domain alignment: Bayesian priors excel under data scarcity, while meta-learning transformers scale better with complex, heterogeneous features.
Key Takeaways:
- Medical domain: TabPFN (SFT, rank 1.86) achieves best overall accuracy, with its meta-learning variant (rank 2.28) maintaining robustness; TabDPT (PEFT–SFT, rank 1.96) offers strong low-cost alternatives
- Finance domain: OrionMSP (meta, rank 2.26, ACC ≈0.82) achieves top results, closely followed by TabPFN (meta/SFT, ranks 2.00–3.00); TabDPT (PEFT–SFT) remains efficient and competitive.
- Cross-domain: TabPFN provides most consistent cross-domain performance; OrionMSP generalizes best to large-scale financial data; meta-learning and PEFT yield stable, domain-adaptive transfer.
6.3 Calibration Evaluation
Reliable probability calibration is essential for deploying tabular models in real-world decision-making systems. Calibration measures how well predicted probabilities align with observed outcomes, ensuring that model confidence reflects actual likelihoods. We evaluate Expected Calibration Error (ECE), Maximum Calibration Error (MCE), and Brier Score (BS) across all benchmark suites—TALENT, OpenML-CC18, and TabZilla—under different adaptation strategies. Lower values indicate better calibration. Table 8 summarizes the results and highlights how fine-tuning affects probabilistic reliability.
Zero-shot inference
Pretrained tabular foundation models (TFMs) achieve the strongest overall calibration without fine-tuning. OrionMSP and TabICL obtain the lowest ECE (0.0219 on TALENT) and maintain low BS values (≈0.15). OrionMSP further sustains excellent calibration on OpenML-CC18 (ECE=0.0319, BS=0.1262) and TabZilla (ECE=0.0310, BS=0.1243), ranking first or tied across suites. TabPFN remains consistently well-calibrated (ECE=0.0276–0.0431, BS=0.125–0.151), confirming the reliability of its Bayesian uncertainty modeling. TabDPT performs respectably (ECE≈0.03–0.04, BS≈0.12–0.16), while Mitra shows extreme miscalibration (ECE>0.19, BS>0.52), indicating unreliable confidence outputs.
Meta-learning fine-tuning
Episodic meta-learning largely preserves calibration quality. TabPFN achieves the best overall calibration across suites (ECE=0.0271–0.0388, BS=0.118–0.150), improving slightly over zero-shot results. OrionMSP remains competitive (ECE=0.0340–0.0365, BS=0.125–0.166), maintaining stable confidence estimates even after adaptation. In contrast, transformer-heavy models such as TabICL exhibit severe degradation on TabZilla (ECE rises from 0.0369 to 0.2033), showing that full episodic updates can destabilize latent priors when domain variability is high. Interestingly, Mitra improves calibration dramatically under meta-learning (ECE drops from ≈0.22 to 0.03–0.05), although its Brier scores remain poor (>0.34), suggesting partial correction without overall reliability gains.
Supervised fine-tuning (SFT)
Full SFT substantially worsens calibration for most transformer models. TabICL’s ECE triples to quadruples (0.02–0.04 → 0.08–0.15) and its Brier Score deteriorates from ≈0.15 to 0.23–0.41. OrionBiX follows a similar pattern. OrionMSP maintains moderate calibration (ECE=0.047–0.077, BS=0.21–0.26)—still degraded but markedly better than other transformers. TabPFN, however, preserves excellent reliability: across all suites, it records ECE=0.0287–0.0469, MCE<0.30, and BS=0.124–0.158, closely matching or outperforming its zero-shot performance. TabDPT also retains good calibration (ECE=0.0497–0.0713, BS=0.144–0.186). Mitra again performs worst (ECE > 0.15, BS > 0.47), underscoring structural limitations in its confidence estimation.
Discussion
Calibration analysis reveals a clear hierarchy of reliability. TabPFN consistently exhibits the lowest ECE and Brier Scores across all adaptation strategies, validating its Bayesian design and robustness to parameter updates. Meta-learning preserves calibration better than full SFT, confirming that episodic adaptation reinforces pretrained uncertainty priors. OrionMSP achieves strong calibration, especially under zero-shot and meta-learning, while transformer-centric models like TabICL and OrionBiX show pronounced drift once fully fine-tuned. Overall, TFMs maintain lower calibration error than ensemble baselines and degrade far less under fine-tuning, making them more trustworthy for risk-sensitive deployment.
Key Takeaways:
- TabPFN maintains excellent calibration across all strategies (ECE 0.027–0.047, BS 0.12–0.15), confirming its Bayesian reliability; TabDPT (SFT) and OrionMSP (zero-shot/meta-learning) rank next best (ECE 0.0219–0.0365)
- Supervised fine-tuning degrades calibration for transformer models: TabICL’s ECE increases 3–4× and BS deteriorates sharply, while OrionMSP degrades moderately.
- Zero-shot inference yields the best calibration overall, with OrionMSP and TabPFN showing ECE < 0.04 across all suites.
6.4 Fairness Evaluation
Fairness analysis evaluates whether model predictions exhibit systematic bias across demographic subgroups, complementing accuracy and calibration assessments by addressing equity in high-stakes applications such as lending, healthcare, and criminal justice. Unlike performance metrics that can be computed automatically, fairness requires explicit identification of sensitive attributes (e.g., race, gender, age, income). We use datasets with demographic labels—Adult Census Income, German Credit, and COMPAS Recidivism—to measure bias propagation and mitigation across strategies. Following standard fairness literature, we report Statistical Parity Difference (SPD), Equalized Odds Difference (EOD), and Equalized Opportunity Difference (EOpD). All metrics are absolute differences in the 0–1 range (lower = fairer). Table 9 summarizes fairness–accuracy trade-offs across zero-shot, meta-learning, and fine-tuning strategies.
Zero-shot inference.
A clear fairness–accuracy trade-off emerges. Mitra achieves the lowest bias (SPD =0.0193, EOD =0.0590, EOpD =0.0982) but with very low predictive accuracy (ACC = 0.6902). OrionMSP and OrionBiX balance fairness and accuracy best, maintaining high accuracy (ACC = 0.875-0.878) and moderate fairness (EOD =0.27–0.28). TabPFN shows consistent behavior (ACC = 0.871, SPD = 0.307), while ContextTab ranks second in fairness (SPD =0.208) at slightly lower accuracy. These results suggest that transformer-based models preserve competitive fairness even without task-specific adaptation.
Meta-learning fine-tuning.
Episodic adaptation largely preserves fairness while sustaining accuracy. OrionBiX achieves the lowest overall bias (SPD = 0.2021, EOD = 0.1624, EOpD = 0.2010) while maintaining high accuracy (ACC = 0.8743). OrionMSP follows closely (EOD = 0.2798, EOpD = 0.2907), offering the best fairness–accuracy equilibrium across models. TabPFN achieves the highest accuracy (ACC = 0.8733) with slightly higher disparity (SPD ≈ 0.31). Mitra remains highly fair but again sacrifices accuracy. Overall, meta-learning fine-tuning maintains fairness levels similar to zero-shot inference while modestly improving accuracy consistency.
Supervised fine-tuning (SFT).
Full SFT produces mixed fairness outcomes. Mitra again records the lowest bias (SPD =0.0161, EOD =0.0170) but with only ACC = 0.7268. TabICL exhibits striking fairness gains (SPD drops from 0.29 to 0.055) yet loses over 40% in accuracy (ACC = 0.4584). OrionBiX improves fairness (EOD = 0.1761) but suffers large accuracy loss (ACC = 0.618). In contrast, TabPFN maintains both high accuracy (ACC = 0.8733) and moderate, stable fairness metrics across all strategies, confirming robustness. TabDPT ranks second in accuracy (ACC = 0.8529) with fairness levels comparable to TabPFN. These results underscore that SFT can reduce group disparity for some models but typically harms predictive reliability.
Parameter-efficient fine-tuning (PEFT).
PEFT variants show similar patterns while retaining higher stability. Under PEFT meta-learning, OrionBiX and OrionMSP achieve balanced fairness (EOD ≈ 0.27–0.28) and strong accuracy (ACC = 0.867–0.875), outperforming full SFT counterparts. Under PEFT SFT, Mitra again minimizes bias (SPD = 0.0029) but accuracy remains low (ACC = 0.7133). TabDPT delivers the best accuracy–fairness compromise (ACC = 0.8595, SPD ≈ 0.30). Overall, PEFT preserves fairness trends while mitigating the accuracy collapse observed in full fine-tuning.
Discussion.
Fairness evaluation confirms a fundamental accuracy–equity trade-off. Models achieving near-perfect demographic parity (Mitra, SPD <0.02) incur large accuracy losses, while TabPFN and OrionMSP consistently achieve balanced performance. Meta-learning proves most stable, preserving both fairness and accuracy across suites. SFT can occasionally improve parity for specific transformer architectures but typically at the expense of predictive fidelity. PEFT provides an effective compromise, maintaining high accuracy and moderate bias without significant fairness degradation.
Key Takeaways:
- Accuracy–fairness trade-off: Mitra attains best fairness (SPD = 0.0029–0.0193) but suffers low accuracy (ACC = 0.69–0.73).
- Balanced models: TabPFN and OrionMSP offer the best fairness–accuracy equilibrium (ACC = 0.87–0.88, EOD =0.27–0.29), outperforming other TFMs.
- Effect of fine-tuning: SFT improves fairness for some models (e.g., TabICL SPD 0.055 vs 0.29 zero-shot) but drastically reduces accuracy; meta-learning preserves both aspects better.
- PEFT stability: Parameter-efficient strategies maintain fairness trends while retaining high accuracy, offering a pragmatic balance for equitable deployment.
7 Discussion
Our comprehensive analysis across three benchmark suites reveals clear patterns that guide model selection, adaptation strategy, and deployment trade-offs.
7.1 Fine-Tuning Strategy Recommendations
Fine-tuning strategy choice is critical and highly model-dependent.
- Zero-shot inference achieves excellent calibration (ECE <0.04 for top models) and competitive predictive performance for OrionMSP and TabPFN. It is ideal when computational resources are limited or calibration reliability is a priority. Zero-shot OrionMSP achieves strong accuracy on large datasets (ACC = 0.8722–0.8821, ranks 3.26–3.84) and top performance on OpenML-CC18 and TabZilla without requiring additional training.
- Meta-learning fine-tuning provides the best balance between adaptation and generalization. It improves rank stability (OrionMSP: ranks 1.73–2.82 vs. 2.90–3.84 in zero-shot) while preserving calibration (ECE <0.06). Meta-learning also excels in high-imbalance financial data (OrionMSP ranks 2.26, TabPFN ranks 3.00), confirming its cross-domain robustness. However, instability can occur for some models such as TabICL on TabZilla (ECE increases to 0.2033), requiring careful validation.
- Supervised fine-tuning (SFT) delivers the strongest results for TabPFN (ranks 1.83–1.89, ACC up to 0.9346 on wide datasets). In contrast, SFT causes substantial degradation for TabICL and OrionBiX: for instance, TabICL’s accuracy on TabZilla falls from 0.8734 to 0.5670, indicating severe overfitting. Calibration also deteriorates (ECE 0.08–0.15 vs. 0.02–0.04 zero-shot). SFT should therefore be used selectively—beneficial for TabPFN, acceptable for TabDPT and OrionMSP, but risky for TabICL and OrionBiX.
- Parameter-efficient fine-tuning (PEFT) attains nearly full fine-tuning accuracy while greatly reducing computational cost. TabDPT achieves high performance (ACC≈0.85, F1≈0.84) across all benchmarks, and OrionMSP maintains competitive accuracy (ACC≈0.82–0.86, F1≈0.80–0.85) with strong cross-dataset generalization.
7.2 Mechanisms Behind Fine-Tuning Performance
The varying outcomes of different fine-tuning strategies can be explained by the underlying adaptation mechanisms.
Why SFT Underperforms for TabICL and OrionBiX?
Full supervised fine-tuning updates all model parameters, erasing pretrained representations—especially detrimental on smaller datasets. The performance collapse of TabICL on TabZilla (ACC 0.8734→0.5670) exemplifies overfitting and representation drift, whereas optimization distorts pretrained priors. Both TabICL and OrionBiX rely on high-capacity transformer layers optimized for diverse pretraining data; constraining them to a narrow distribution leads to loss of generality and inflated variance in predictions.
Why Meta-Learning Preserves Generalization?
Episodic training in OrionMSP and TabPFN aligns closely with the few-shot adaptation process. Each meta-episode simulates the support–query dynamics of deployment, encouraging transfer of cross-task features rather than memorization. This prevents catastrophic forgetting and reinforces pretrained inductive biases. The improvement in rank stability for OrionMSP (from 2.90–3.84 in zero-shot to 1.73–2.82 in meta-learning) confirms that episodic optimization promotes stable generalization.
When Fine-Tuning is Beneficial?
Fine-tuning is most useful when:
- Datasets are sufficiently large (>10K samples), mitigating overfitting
- Domain distribution shifts significantly from pretraining data (e.g., medical, finance).
- Architecture maintains calibration under parameter updates (as in TabPFN’s Bayesian prior design).
For small or balanced datasets, zero-shot or meta-learning is more reliable and cost-efficient. Parameter-efficient fine-tuning (PEFT) provides a strong middle ground, retaining ≈95% of full SFT accuracy while reducing memory.
7.3 Calibration Insights
Our calibration analysis shows that TabPFN uniquely maintains excellent calibration across all fine-tuning strategies (ECE 0.027–0.047, BS 0.12–0.16), validating its Bayesian uncertainty formulation. This makes TabPFN ideal for high-stakes domains such as healthcare and finance. Meta-learning further stabilizes calibration—TabPFN’s ECE improves slightly under episodic updates, and OrionMSP remains well-calibrated (ECE <0.06). In contrast, TabICL exhibits the largest degradation under SFT (ECE increases 3–4×, BS rises to 0.23–0.41), confirming that full parameter updates distort uncertainty estimates. For calibration-critical applications, we recommend TabPFN (any regime) or OrionMSP (meta-learning); SFT should be avoided for TabICL and OrionBiX.
7.4 Model Selection Guidelines
Model selection should be guided by dataset scale, balance, feature dimensionality, and available computational resources. All recommendations below are derived from the common subset of datasets evaluated across all models to ensure consistent statistical comparison. Reported values combine mean accuracy (ACC), weighted F1-score (F1), and mean rank (based on accuracy) as presented in Tables 3–6.
General Guidelines:
When dataset characteristics are unknown, zero-shot inference with OrionMSP or meta-learning fine-tuning with TabPFN serve as the most reliable defaults. Both models consistently achieve top-three average ranks across all benchmark suites while maintaining strong calibration and fairness. In general:
- TabPFN provides the most consistent accuracy and F1 across diverse data regimes, excelling in calibration and few-shot generalization.
- OrionMSP scales best on large, complex, and imbalanced datasets, particularly under meta-learning.
Specific Regime Recommendations.
- Small datasets (<1K samples): TabPFN achieves the best results in both zero-shot and meta-learning settings (ACC = 0.8325–0.8336, F1 = 0.8131–0.8256, ranks <2.5)), effectively capturing few-shot patterns without fine-tuning. Zero-shot OrionMSP offers a robust alternative for rapid deployment (ACC = 0.8232, F1 = 0.8194). Fine-tuning transformer-based models such as TabICL or OrionBiX should be avoided on small datasets due to severe overfitting.
- Medium datasets (1K–10K samples): TabPFN with meta-learning achieves the highest mean accuracy (ACC = 0.8638, F1 = 0.8548, rank ≈2.0), followed closely by its supervised fine-tuning variant (ACC = 0.8580, F1 = 0.8485). When computational constraints are present, TabDPT (PEFT–Meta) maintains competitive accuracy (ACC = 0.8121–0.8332) with minimal resource overhead. Zero-shot inference remains a practical option for quick deployment, trailing fine-tuned variants by only about 2–3% in accuracy.
- Large datasets (>10K samples): OrionMSP in zero-shot mode delivers the highest mean performance among TFMs (ACC = 0.8843, F1 = 0.8768, rank ≈2.0). TabDPT (zero-shot or PEFT–SFT) achieves comparable accuracy (ACC = 0.8496–0.8831) while offering lower adaptation cost. Classical models such as XGBoost and CatBoost reach strong absolute accuracies (ACC = 0.8969, F1 = 0.8920) but exhibit poorer calibration and higher cross-dataset variance. TFMs are therefore more advantageous when generalization consistency or uncertainty estimation is prioritized.
- Balanced datasets: TabPFN under supervised fine-tuning yields the best average rank (1.96) with ACC = 0.8336, F1 = 0.8267, followed by OrionMSP under meta-learning (rank 2.27). Balanced data favor Bayesian or episodically fine-tuned architectures, which maximize calibration and stability.
- Imbalanced datasets: Meta-learning strategies provide the most robust adaptation under label imbalance. OrionMSP achieves the best overall performance (rank = 2.16, ACC = 0.8735, F1 = 0.8636), with TabPFN ranking second (rank = 2.50, ACC = 0.8784, F1 = 0.8664). These results confirm that episodic training improves minority-class calibration. In contrast, tree-based baselines lose roughly 3–5% in F1 when class ratios fall below 0.6.
- Low-to-medium feature dimensionality (<100 features): Model performance converges across methods (ACC = 0.84–0.86), with TabPFN (Meta Learning) and OrionMSP (Zero-Shot) performing most consistently. In this regime, TFMs primarily outperform classical methods in calibration and rank stability rather than raw accuracy.
- High-dimensional datasets (>100 features): TabPFN under supervised fine-tuning achieves the highest overall scores (ACC = 0.9346, F1 = 0.9335), significantly surpassing other models. TabDPT and OrionMSP maintain strong accuracy (ACC ≈ 0.84–0.89) while offering superior efficiency. Architectures such as TabICL and OrionBiX exhibit sharp performance drops under full fine-tuning, confirming their susceptibility to overfitting in wide-feature settings.
Key Takeaways
- For inference-only deployment, use OrionMSP (Zero-Shot) or TabPFN (Zero-Shot) for balanced accuracy and calibration.
- For adaptive fine-tuning, prefer TabPFN (SFT/Meta) on small–to–medium datasets and OrionMSP (Meta) on large-scale or imbalanced data.
7.5 Domain-Specific Guidance
Medical domain: TabPFN achieves the strongest performance in this domain, with its supervised fine-tuning configuration attaining Rank = 1.86 and ACC = 0.8094, closely followed by the meta-learning variant (Rank = 2.28, ACC = 0.8133). TabDPT under PEFT–SFT (Rank = 1.96) provides competitive accuracy at substantially lower computational cost. Transformer-based architectures such as TabICL and OrionBiX exhibit notable degradation under full fine-tuning, reflecting sensitivity to small and noisy clinical datasets. Overall, Bayesian and episodically trained models generalize more reliably in data-scarce medical settings.
Finance domain: OrionMSP under meta-learning achieves the best overall results (Rank = 2.16, ACC = 0.8209, F1 = 0.8128), followed closely by TabPFN (Meta/SFT, Ranks = 2.50–2.89, ACC = 0.8162–0.8784). TabDPT remains competitive (PEFT–SFT, Rank = 2.82) and offers an efficient alternative with only a minor loss in accuracy. These outcomes confirm that episodic and parameter-efficient adaptation strategies are particularly effective for large-scale, class-imbalanced financial data, where they improve both calibration and minority-class performance.
7.6 Practical Value of Tabular Foundation Models
Tabular Foundation Models (TFMs) deliver consistent but moderate absolute accuracy improvements—typically 2–4 percentage points—over strong classic baselines such as XGBoost, CatBoost, and LightGBM. Across comparable settings, TFMs achieve mean accuracies around 0.85–0.88 versus 0.83–0.86 for boosted trees. However, their primary advantage lies in reliability and robustness rather than raw accuracy.
Key strengths include: (I) Zero-shot adaptability: OrionMSP achieves top-tier zero-shot performance (ACC = 0.8722–0.8821, overall rank ≈3.5) without any task-specific training. (II) Calibration: TabPFN maintains low calibration error (ECE <0.05) across both zero-shot and fine-tuned regimes, outperforming ensemble baselines whose ECE often exceeds 0.08. (III) Fairness stability: TFMs achieve moderate statistical parity differences (SPD ≈0.28–0.30) while sustaining high accuracy (>0.85), indicating balanced performance across sensitive groups.
Consequently, TFMs should be regarded as reliable, general-purpose learners well suited for rapid deployment, few-shot adaptation, and risk-sensitive applications where calibration and fairness are critical. For large, well-labeled, single-domain problems, gradient-boosted trees may still be preferable for simplicity and computational efficiency, but TFMs offer distinct advantages in uncertainty estimation, cross-domain generalization, and calibration consistency.
7.7 Limitations
While TabTune provides broad support for evaluating and fine-tuning TFMs, several limitations remain.
Task Scope: Current support is limited to binary and multi-class classification tasks; regression and multi-label extensions are planned for future releases.
Model Constraints:
- Dataset size: TabPFN performs optimally on datasets with fewer than 10,000 samples; larger datasets may significantly increase inference latency or exceed memory limits
- Dimensionality: All models can degrade when the feature space exceeds ∼1000 dimensions without preprocessing or feature selection.
- PEFT compatibility: Parameter-efficient fine-tuning is fully supported for OrionMSP and TabDPT, but only partially implemented for TabPFN and ContextTab.
- ContextTab evaluation: Due to excessive GPU memory requirements, ContextTab was evaluated only on smaller benchmark subsets.
Evaluation and Analysis:
- Manual fairness specification: Sensitive attributes are manually defined per dataset, introducing potential bias in fairness evaluation.
- Calibration interpretation: Optimal threshold tuning remains domain-dependent and may vary across metrics or class distributions.
- Beyond-accuracy metrics: Advanced interpretability, reliability, and uncertainty quantification metrics are not yet fully integrated into the current release.
8 Conclusion
We introduce TabTune, a unified Python library that standardizes the workflow for tabular foundation models (TFMs). By abstracting model-specific preprocessing, consolidating adaptation strategies, and integrating evaluation modules for performance, calibration, and fairness, TabTune addresses the fragmentation that has limited the broader adoption of TFMs. Inspired by AutoML, TabTune focuses on managing and optimizing pretrained TFMs rather than building models from scratch, offering a coherent framework for efficient adaptation and assessment.
We conducted a comprehensive study on the performance of tabular foundation models (TFMs) and the impact of fine-tuning strategies on their effectiveness. The empirical analysis demonstrates that the choice of adaptation strategy is highly model-dependent. TabPFN performs optimally under supervised fine-tuning or meta-learning, OrionMSP exhibits strong generalization and robustness particularly with meta-learning, and TabDPT using parameter-efficient fine-tuning (PEFT) achieves a favorable balance between predictive accuracy and computational efficiency. Beyond raw performance, our findings emphasize the reliability and fairness of TFMs. TabPFN consistently attains excellent calibration, while both OrionMSP and TabPFN maintain a strong fairness–accuracy balance, reinforcing their potential for responsible and trustworthy deployment in high-stakes domains.
9 Future Work
As an extensible and reproducible platform for TFM research, TabTune continues to evolve to support emerging methodologies and broader evaluation dimensions. Future work will focus on integrating more advanced fine-tuning and meta-learning approaches to enhance few-shot and domain adaptation capabilities. In parallel, we aim to strengthen the evaluation framework by incorporating modules for advanced fairness assessment, interpretability, and uncertainty quantification. Additionally, we plan to extend task coverage beyond binary and multi-class classification to include regression, multi-label learning, and time-series modeling. By standardizing the TFM workflow, TabTune enables practitioners to transition efficiently from experimentation to reliable deployment, fostering evidence-based model selection and accelerating the responsible adoption of foundation models in structured data domains.