1 Introduction
Tabular data remain the most prevalent form of data in real-world applications, spanning critical systems across healthcare, finance, and scientific research. Despite the remarkable progress of deep learning in natural language processing [27, 42] and computer vision [11], gradient boosted trees (GBTs) remain the predominant state-of-the-art (SOTA) for tabular prediction tasks. In other data modalities, foundation models—particularly Large Language Models (LLMs) [46, 26]—have significantly advanced the ability to tackle new tasks and few-shot learning. This is largely due to their remarkable in-context learning (ICL) capabilities [45, 4], which enable them to capture patterns directly from prompts without updating their parameters. This success combined with the pervasiveness of tables have spurred interest in tabular foundation models [38].
Although LLMs are primarily designed to process natural language, recent efforts have explored fine-tuning them for tabular data tasks [14, 8]. These approaches typically rely on table serialization, which is the process of converting table rows into text or sentences suitable for tokenization. For instance, [9] fine-tuned a Llama 3-8B model on a large corpus of serialized tables and demonstrated that this strategy can outperform traditional tree-based models in few-shot scenarios. However, such language model–based approaches face inherent challenges. Their limited context windows restrict the number of serialized examples that can be processed simultaneously (e.g., up to 32 or 64 shots in [9]), and it remains uncertain whether LLMs can reliably interpret and reason over numerical values [37].
Adopting a fundamentally different strategy, the authors of [16] introduced TabPFN, a transformer-based tabular foundation model designed for classification tasks and pretrained exclusively on synthetic tabular data. A key feature of TabPFN is its ability to perform in-context learning directly on tables, removing the need for tokenization and allowing efficient processing of relatively small datasets—up to 1K samples and 100 features. Building on this foundation, TabICL [32] introduced a simplified three-component architecture comprising: (1) column-wise embeddings via Set Transformers to capture distribution-aware feature semantics, (2) row-wise interactions with rotary positional encodings to model inter-feature dependencies, and (3) dataset-level ICL prediction through split attention, ensuring a clear separation between training and test samples. These developments position tabular foundation models as a compelling alternative to traditional approaches, particularly for zero-shot prediction tasks where dataset-specific training is infeasible.
However, current table-native ICL architectures face several fundamental limitations that hinder their practical deployment and scalability. First, existing tabular ICL architectures, including TabICL, process features uniformly at a single scale, missing hierarchical interaction patterns that naturally occur in real-world tabular data. Just as computer vision benefits from multi-scale processing—capturing edges at fine scales and objects at coarse scales—tabular data exhibits structure at multiple granularities: individual features interact locally (e.g., age and income), feature clusters form semantic groups (e.g., demographic attributes), and high-level blocks represent major data divisions (e.g., personal attributes versus behavioral patterns). Processing all features uniformly fails to capture these hierarchical relationships, limiting the model’s ability to learn robust and interpretable representations.
Second, the dense attention mechanisms scale quadratically with feature count (O(m2)), where m denotes the number of features. While TabICL addresses sample scalability through its column-then-row architecture, the quadratic feature complexity becomes computationally prohibitive for high-dimensional tables with more than 100 features common in genomics, finance, and sensor applications. For tables with m=100 features, dense attention requires 10,000 attention operations per layer, with memory requirements growing quadratically. This fundamental scalability barrier limits the practical deployment of tabular foundation models on wide real-world datasets.
Third, the strictly sequential processing pipeline in TabICL (column embedding → row interaction → ICL prediction) prevents iterative refinement and bidirectional information flow between architectural components. While each component produces rich representations, the unidirectional nature of the pipeline means that downstream insights (e.g., dataset-level patterns discovered during ICL) cannot inform upstream representations (e.g., refining feature embeddings based on dataset context). This limitation constrains the model’s ability to leverage holistic dataset understanding for improved predictions, and prevents the kind of iterative refinement that has proven beneficial in multimodal architectures.
To address these limitations, we introduce Orion-MSP, a novel tabular foundation model that extends TabICL with three synergistic architectural innovations. First, we propose multi-scale hierarchical feature processing that simultaneously captures interactions at multiple granularities (individual features, groups of 4, and groups of 16), enabling the model to learn representations at different levels of abstraction analogous to hierarchical processing in computer vision. Second, we design structured block-sparse attention patterns combining windowed local attention, global tokens for long-range dependencies, and random connectivity for universal approximation, reducing computational complexity from O(H2) to O(H.logH) while maintaining expressiveness. Third, we introduce Perceiver-style cross-component memory that enables bidirectional information flow between architectural stages while provably maintaining in-context learning safety constraints—ensuring test data never influences training representations through formal ICL safety analysis.
The column-wise embedding component of Orion-MSP follows TabICL’s approach [32], using Set Transformers with Induced Set Attention Blocks (ISAB) [25] to create distribution-aware feature embeddings in a permutation-invariant manner. The multi-scale row interaction component processes these embeddings at multiple resolutions, with each scale using sparse attention patterns tailored to its granularity. The resulting multi-scale representations are aggregated into unified row embeddings, which then interact with the Perceiver memory before proceeding to the final ICL prediction stage. This ICL component employs split attention with label injection, ensuring proper train-test separation.
Through extensive experiments across diverse tabular benchmarks, we demonstrate that Orion-MSP achieves competitive accuracy with state-of-the-art tabular ICL methods while enabling scalability to tables with more than 100 features where existing methods fail due to memory constraints. Our work establishes that hierarchical multi-scale processing, structured sparsity, and cross-component memory can simultaneously improve both effectiveness and efficiency in tabular foundation models, opening new application domains previously inaccessible to tabular in-context learning methods.
2 Related Work
Tabular In-Context Learning: The application of in-context learning (ICL) to tabular data has recently attracted significant attention. TabPFN [16] pioneered this direction by meta-training a transformer on synthetically generated datasets using structural causal models. Its encoder–decoder design allows test samples to attend to training examples, enabling zero-shot predictions without gradient-based fine-tuning. While TabPFN demonstrated strong performance on small datasets, its alternating column- and row-wise attention mechanisms make scaling to larger tables computationally prohibitive.
TabDPT [28] showed that comparable performance can be achieved on real-world datasets by using similarity-based retrieval to construct contextual examples—an idea first explored in TabR [12]. The authors extended this paradigm by integrating diffusion-based representation learning, improving robustness to missing values and distributional shifts. However, the diffusion process introduces substantial computational overhead and retains dense attention, limiting scalability. Similarly, TabPFN-v2 [17] introduced cell-based in-context learning, extending row-wise encoding to datasets exceeding 10,000 samples, but it still inherits quadratic attention costs in high-dimensional tables.
Building on these foundations, TabICL [32] proposed a table-native transformer architecture with three components: column embedding via Set Transformers, row-wise interaction with rotary positional encodings, and an in-context learning prediction module. This design achieved state-of-the-art results across diverse benchmarks while maintaining architectural simplicity and training efficiency. Nonetheless, dense attention in row interactions and the strictly sequential pipeline limit iterative refinement, cross-component communication, and scalability to tables with more than 100 features.
ContextTab [35] further enhanced tabular in-context learning by incorporating contextualized feature embeddings and attention mechanisms tailored for heterogeneous tabular data. While improving performance in complex datasets, it still processes features at a single scale and relies on dense attention, limiting computational efficiency on high-dimensional tables.
Collectively, existing tabular in-context learning models demonstrate strong performance yet share core limitations: dense quadratic attention, uniform single-scale processing, and lack of cross-component feedback.
Sparse Attention Mechanisms: Sparse attention techniques from natural language processing offer a promising route to improve computational efficiency in tabular in-context learning. BigBird [43] and Longformer [1] demonstrated that block-sparse attention patterns can approximate dense attention with linear complexity while maintaining strong theoretical guarantees. Similarly, Sparse Transformers [5, 20] employ structured sparsity for generative modeling, reducing computation without substantial performance degradation. Despite their success in sequential data, these methods have yet to be systematically adapted for tabular in-context learning, where the primary challenge lies in feature dimension rather than sequence length.
Hierarchical and Multi-Scale Architectures: Hierarchical architectures have proven effective in other domains. Funnel Transformers [6] and Swin Transformers [30] use multi-scale processing and pooling to capture information at different resolutions, while Set Transformers [34, 10] leverage pooling by multihead attention for permutation-invariant set processing. Although TabICL [32] employs Set Transformers for column embeddings, it does not incorporate hierarchical multi-scale processing or iterative pooling across feature groups, limiting its ability to model complex interactions in high-dimensional tables.
Cross-Component Communication: Cross-component memory and iterative refinement have shown success in multimodal learning. Perceiver [19] and Perceiver IO [18] introduce latent bottlenecks to compress and share information across modalities, and vision-language models [39] leverage iterative cross-attention for refinement. However, these approaches do not address the causal constraints of in-context learning, where test examples must never influence the representation of training data, leaving a gap for tabular in-context learning.
3 Proposed Approach: Orion-MSP
3.1 Problem Formulation
3.2 High-level Structure: From Data to ICL
Orion-MSP consists of four core components that collectively enable efficient and generalizable tabular in-context learning: (1) Column Embedding: transforms raw tabular features into dense, semantically meaningful representations; (2) Multi-Scale Sparse Row Interaction: captures dependencies at multiple granularities via an hierarchy of attention scales, combining CLS and GLOBAL tokens for local and long-range connectivity; (3) Cross-Component Perceiver Memory: introduces a latent memory bottleneck that enables safe bidirectional communication between modules, promoting iterative refinement without information leakage; (4) Dataset-wise In-Context Learning Predictor: leverages the enriched representations to perform zero-shot prediction across new tasks without gradient updates. An overview of the complete architecture is shown in Figure 1.
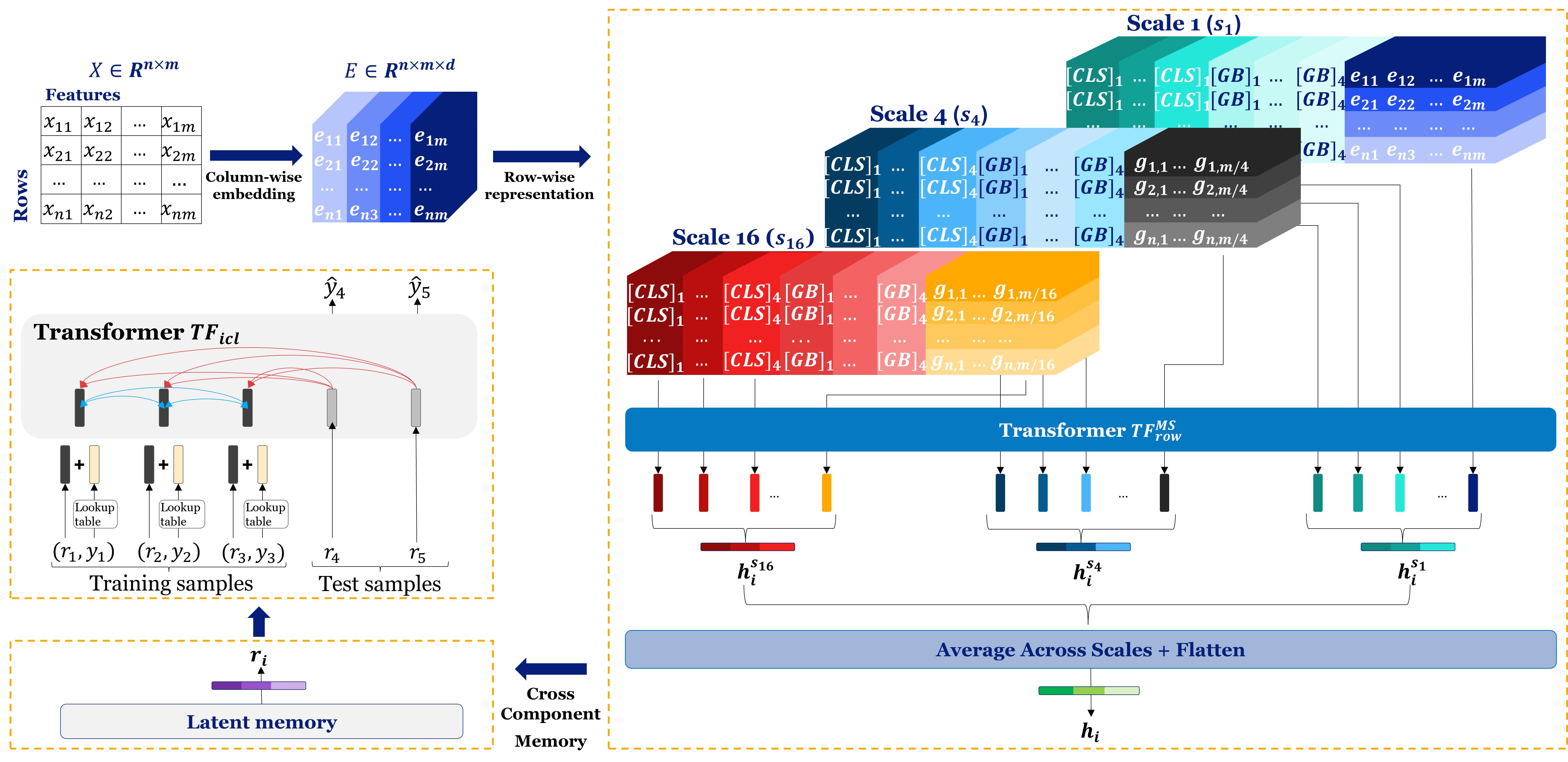
Orion-MSP extends the original TabICL [32] architecture with three complementary innovations designed to address the fundamental challenges of tabular data processing: computational inefficiency, limited feature interaction modeling, and the need for hierarchical pattern recognition. Our approach maintains the core in-context learning paradigm while introducing architectural enhancements that significantly improve both efficiency and performance.
3.3 Column-wise Embedding
3.4 Multi-Scale Sparse Row-Wise Interaction
While column-wise embedding captures distributional properties of individual features, row-wise interaction must model complex dependencies across features to extract meaningful sample representations. However, directly applying dense self-attention to all feature tokens incurs quadratic complexity O(m2) and may overfit when the number of features varies significantly across datasets. To address these challenges, we introduce a hierarchical multi-scale sparse attention mechanism that processes features at multiple granularities with efficient block-sparse patterns.
3.4.1 Motivation and Design Principles
Tabular datasets exhibit several unique characteristics that complicate feature interaction modeling:
- Variable feature counts: The number of features m varies dramatically across datasets, making fixed-scale architectures suboptimal.
- Heterogeneous feature relationships: Some features interact locally (e.g., age and age-related health metrics), while others have global dependencies (e.g., categorical indicators).
- Computational constraints: Dense attention over m features has complexity O(m2), becoming prohibitive for wide tables or long context windows.
- Overfitting risks: Full attention can memorize training-specific feature correlations that do not generalize to new datasets.
Inspired by hierarchical representations in vision [41] and multi-resolution modeling in speech [44], Orion-MSP decomposes feature interactions into multiple resolution levels:
- Fine scale (s=1): Captures detailed pairwise dependencies between individual features.
- Coarse scales (s>1): Aggregates semantically related features into groups, reducing sequence length and enabling broader contextual reasoning.Scale aggregation: Combines representations across scales to balance local precision and global context.

To further improve efficiency and generalization, we adopt a block-sparse attention pattern inspired by Longformer [1] and BigBird [43], as depicted in Figure 2:
- Sliding window attention: Local connectivity within a fixed radius w, preserving fine-grained structure.
- Global tokens: Specialized tokens with full connectivity, ensuring stable long-range information flow.
- Random links: Optional sparse stochastic connections that enhance expressivity and global reachability.
3.5 Cross-Component Memory with Perceiver Architecture
While the column-wise embedding and row-wise interaction components of tabular transformers independently model feature- and sample-level dependencies, richer contextual understanding can emerge if information is shared across these components. However, direct cross-component communication poses a major risk to the in-context learning (ICL) paradigm: naive attention between components can leak test-set information, violating the principle that predictions for test samples must depend solely on training examples and the test input itself.
To overcome this limitation, we introduce a Perceiver-style latent memory module [19] that enables safe, leak-free communication between architectural components. This latent memory acts as a shared representation space that can be written to by training samples and read from by both training and test samples, ensuring compliance with ICL constraints while promoting global knowledge sharing.
In standard transformer-based tabular architectures such as TabICL [32], model components operate in a strictly sequential and isolated fashion:
- Column Embedding (TFcol): Encodes feature-wise statistics across samples to capture column-level distributions.
- Row Interaction (TFrow): Models dependencies across features within each sample.
- ICL Prediction (TFicl): Performs in-context learning to infer test labels from training examples.
This separation simplifies optimization and ensures ICL safety, but also introduces significant limitations:
- No backward adaptation: Column embeddings cannot adjust based on row-level feature interactions.
- Limited contextual refinement: Row-level interactions lack access to global, dataset-level statistics beyond static column embeddings.
- Dataset isolation: Each dataset is processed independently, preventing cross-dataset generalization within a batch.
A fundamental ICL constraint is that test samples must not influence the model’s internal state in a way that affects training representations. Formally, letting
This asymmetric read–write design preserves the integrity of in-context learning:
- Only training samples write to the memory
- Both training and test samples read from it.
- The memory functions as a shared, compressed abstraction of the training data that can be safely leveraged for inference.
The complete ICL forward pass with Perceiver memory is described in Algorithm 2:
3.6 Dataset-wise In-Context Learning
After column-wise embedding, multi-scale sparse row-wise interaction, and optional cross-component memory refinement, each sample is represented by a fixed-dimensional row embedding:

4 Experimental Evaluation
We conduct a comprehensive evaluation of Orion-MSP. Below, we describe our experimental setup and present detailed results.
4.1 Experimental Setting
4.1.1 Benchmark Suites and Datasets.
Our experimental evaluation spans three widely recognized benchmark suites: TALENT [40] (181 automatically discovered classification datasets), OpenML-CC18 [2] (72 curated datasets), and TabZilla [29] (36 heterogeneous tasks). Together, these benchmarks enable a comprehensive assessment across diverse tabular learning scenarios. In addition, we perform domain-specific evaluations in high-impact application areas such as healthcare and finance to examine the real-world relevance of our method. All experiments strictly follow the official dataset splits provided by each benchmark to ensure reproducibility and fairness.
For consistency across model families, results are reported only on the intersection of datasets available to all evaluated models within each benchmark suite. This unified evaluation protocol ensures that observed performance differences arise from methodological advances rather than variations in dataset coverage. After filtering, our evaluation encompasses 154 of 181 datasets from TALENT, 63 of 72 from OpenML-CC18, and 27 of 36 from TabZilla. A small number of datasets were excluded due to out-of-memory (OOM) errors or CUDA-related issues, primarily affecting TabPFN-based architectures even on H200 GPUs.
Finally, we emphasize that models with higher mean ranks may not always achieve the highest absolute accuracy or F1-scores on every dataset. Rankings are computed per dataset and then averaged across all datasets, providing a normalized indicator of overall consistency rather than peak task-specific performance. In contrast, absolute metrics highlight maximum achievable performance on individual tasks. Comprehensive dataset statistics are presented in Appendix A.4.
4.1.2 Models and Baselines.
We compare our model with six state-of-the-art tabular foundation models: TabPFN [16], TabICL [32], OrionBiX, Mitra, ContextTab [35], and TabDPT [28]. In addition, we include established traditional baselines using autogloun [7] such as XGBoost, LightGBM, CatBoost, and Random Forest as strong reference models for comparison.
4.1.3 Hardware Configuration.
Experiments are executed on NVIDIA L40S GPUs, with H200 GPUs used for memory-intensive cases. This infrastructure ensures consistent execution across all experiments while handling the computational demands of large transformer-based models.
4.1.4 Evaluation Metrics.
Our evaluation considers two complementary aspects:
Performance. We measure predictive capability using standard classification metrics—Accuracy (ACC), AUC-ROC, and weighted F1-score (F1)—computed across the benchmark suites TALENT, OpenML-CC18, and TabZilla. These benchmarks encompass datasets with diverse characteristics, including varying sample sizes, feature dimensionalities, and class balance, allowing a comprehensive assessment of model generalization.
Scalability. We further analyze model robustness as dataset complexity increases by examining performance trends with respect to sample size, feature dimensionality, and class imbalance. This analysis uses the same benchmark datasets, aggregated along these axes to reveal systematic scalability behaviors and guide practical model selection.
4.2 Results
Table 1 summarizes results across the TALENT, OpenML-CC18, and TabZilla benchmark suites, reporting mean rank, classification accuracy (ACC), and weighted F1-score (F1) for all evaluated models.
Our experiments confirm that classical machine learning methods remain strong baselines, achieving mean accuracies between 0.833 and 0.861 with aggregated ranks around 6.0. In contrast, pretrained tabular foundation models (TFMs) demonstrate superior generalization, even without task-specific fine-tuning. Notably, our model, Orion-MSP, achieves the best overall zero-shot rank of 3.58, with ACC/F1 scores of 0.8461/0.8360 on TALENT, 0.8722/0.8676 on OpenML-CC18, and 0.8821/0.8786 on TabZilla.
TabPFN follows closely, attaining an overall rank of 4.61 and scores of 0.8514/0.8412 on TALENT and up to 0.8752/0.8716 on TabZilla. TabDPT ranks 5.42, achieving 0.8408/0.8318 on TALENT and 0.8814/0.8775 on TabZilla. By contrast, Mitra (rank 11.77, ACC < 0.40) and ContextTab (rank 9.70) perform substantially worse, highlighting the advantages of hierarchical multi-scale processing and efficient attention in Orion-MSP.
Overall, TabPFN and Orion-MSP emerge as the strongest models, with ACC ranging from 0.85 to 0.88 and ranks between 3.26 and 4.61. Orion-MSP peaks on OpenML-CC18 (rank 4.12, ACC 0.8722) and TabZilla (rank 3.84, ACC 0.8821), while TabPFN leads on TALENT (ACC 0.8514) and maintains stable performance across all benchmark suites.
To further investigate the sources of Orion-MSP’s performance gains, we analyze results across key dataset characteristics. All analyses partition datasets based on inherent properties rather than performance outcomes.
Dataset Size. Table 2 reports model performance aggregated by dataset size: Small (<1K samples), Medium (1K-10K), and Large (>10). Performance trends reveal that Orion-MSP consistently performs well across small, medium, and large datasets. Classical ML models such as XGBoost excel on large datasets due to abundant training examples, achieving the highest ACC/F1 in the >10K sample category. Orion-MSP, however, maintains competitive performance across all size categories, outperforming most baselines on small and medium datasets. This demonstrates the ability of multi-scale sparse attention to generalize effectively in low-data regimes while scaling gracefully to larger datasets. TabPFN also performs strongly, particularly on medium-sized datasets, but Orion-MSP’s consistent performance across size scales highlights the robustness of its hierarchical and sparse design.
Feature Dimensionality. Table 3 presents performance trends across narrow (<10 features), medium (10 - 100) and wide ( >100) datasets. When evaluating dataset width, Orion-MSP shows the highest accuracy on narrow datasets (<10 features) and strong performance on medium and wide datasets (10–100 and >100 features). This suggests that sparse multi-scale attention enables effective learning even in high-dimensional feature spaces, where dense models such as TabICL exhibit diminished scalability to high-dimensional feature spaces.
Based on Class Imbalance. Partitioning datasets based on class balance reveals that Orion-MSP achieves its strongest gains on imbalanced datasets. The model ranks second in this category, achieving ACC = 0.8840 and F1 = 0.8731. This highlights that multi-scale sparse attention amplifies signals from underrepresented classes while avoiding overfitting to dominant classes. On balanced datasets, performance gains are smaller, suggesting that the architectural complexity of Orion-MSP is most advantageous when datasets exhibit skewed distributions. In comparison, TabPFN maintains strong performance on both balanced and imbalanced datasets, but Orion-MSP’s design more effectively addresses minority-class patterns due to hierarchical attention and cross-scale reasoning.
Domain-specific Analysis. Domain-wise evaluation provides deeper insight into Orion-MSP’s strengths (Table 5):
- Medical datasets: Orion-MSP achieves the highest ACC = 0.8045 and F1 = 0.7916, ranking second overall behind Orion-BiX. These datasets often involve hierarchical biological structures and complex interdependencies among features, which align naturally with Orion-MSP’s multi-scale representation. Fine-grained scales capture local dependencies, while coarser scales aggregate contextual information, leading to improved predictive accuracy.
- Finance datasets: Orion-MSP ranks first in mean rank (4.60), achieving ACC = 0.8158 and F1 = 0.8047. Financial datasets frequently involve layered dependencies between assets, instruments, and market indicators. Orion-MSP’s cross-component memory allows information to propagate across scales, capturing global dependencies that standard dense transformers or classical ML models fail to exploit.
Overall, domain-specific results highlight that Orion-MSP excels in high-dimensional, context-rich datasets, where hierarchical patterns and feature correlations are prevalent.
Deep Analysis and Interpretation
A detailed examination by dataset characteristics demonstrates why Orion-MSP’s design is most effective under certain conditions:
- Class imbalance: Multi-scale sparse attention amplifies underrepresented patterns without overfitting to majority classes. Minority-class recognition improves substantially on datasets where the minority class constitutes less than 30% of the data. Balanced datasets show smaller gains, indicating that the hierarchical complexity is most beneficial in skewed settings.
- Hierarchical structure and cross-component memory: In domains such as healthcare and finance, datasets involve natural hierarchies and complex inter-feature relationships. Orion-MSP’s multi-scale design allows it to reason at both fine-grained and coarse-grained levels. Sparse attention reduces computational cost and provides implicit regularization, mitigating overfitting in high-dimensional or correlated-feature settings. Cross-component memory further enables information exchange across scales without violating ICL safety, enhancing performance on context-dependent tasks.
- Computational efficiency: Linear attention complexity with respect to feature number and attention window size allows Orion-MSP to scale to high-dimensional tables. Memory usage grows proportionally with input dimensions, making the model practical for large real-world datasets, unlike dense attention alternatives with quadratic scaling.
In short, fine-grained scales capture subtle minority-class patterns, while coarser scales aggregate global context, yielding a balanced representations of local and global dependencies. Sparse attention improves efficiency and regularization, reducing overfitting in high-dimensional or correlated-feature settings. The Perceiver memory enhances the model’s capacity to store and retrieve non-local patterns, enabling cross-scale reasoning—particularly valuable in context-dependent domains. However, the added architectural complexity offers limited benefit for simpler, low-dimensional datasets, suggesting future directions in adaptive designs with data-driven scale selection and dynamic sparsity control.
5 Conclusion
In this work, we introduced Orion-MSP, a novel tabular in-context learning model that leverages multi-scale sparse attention and cross-component memory to capture both fine-grained and coarse-grained dependencies in tabular data. Through extensive experiments across diverse benchmark suites—including TALENT, OpenML-CC18, and TabZilla—as well as domain-specific datasets in healthcare and finance, we demonstrated that Orion-MSP consistently achieves state-of-the-art zero-shot performance, particularly on imbalanced, high-dimensional, and context-rich datasets.
Our detailed analyses highlight that the hierarchical design, sparse attention, and cross-component memory collectively contribute to robust generalization, efficient computation, and improved representation of complex interdependencies. These architectural choices enable Orion-MSP to outperform existing tabular foundation models in challenging real-world scenarios while maintaining practical scalability.
Nonetheless, we observe that the benefits of multi-scale sparse attention are less pronounced on simple, low-dimensional datasets, where the additional architectural complexity may not be fully leveraged. This limitation motivates future work on adaptive scale selection and data-aware sparsity scheduling, allowing model complexity to adjust dynamically to dataset characteristics. Such extensions could further enhance both efficiency and generality, enabling Orion-MSP to provide strong performance across the full spectrum of tabular learning tasks.
In summary, Orion-MSP represents a promising step toward scalable, adaptive, and context-aware tabular in-context learning, with significant potential for real-world applications and future improvements in dynamic model adaptation.