Abstract
Large neural models are increasingly deployed in high-stakes settings, raising concerns about whether their behavior reliably aligns with human values. Interpretability provides a route to internal transparency by revealing the computations that drive outputs. We argue that interpretability—especially mechanistic approaches—should be treated as a design principle for alignment, not an auxiliary diagnostic tool. Post-hoc methods such as LIME or SHAP offer intuitive but correlational explanations, while mechanistic techniques like circuit tracing or activation patching yield causal insight into internal failures, including deceptive or misaligned reasoning that behavioral methods like RLHF, red teaming, or Constitutional AI may overlook. Despite these advantages, interpretability faces challenges of scalability, epistemic uncertainty, and mismatches between learned representations and human concepts. Our position is that progress on safe and trustworthy AI will depend on making interpretability a first-class objective of AI research and development, ensuring that systems are not only effective but also auditable, transparent, and aligned with human intent.
1. Introduction
AI systems, particularly large language models like ChatGPT and LLaMA (OpenAI, 2024), are increasingly being used in areas that affect people’s lives—healthcare, education, law, and employment among them. These models generate fluent, and useful outputs, but their internal workings remain largely opaque. As a result, it’s difficult to know whether their decisions reflect sound reasoning, accidental correlations, or even actively misaligned goals. This concern has put AI alignment—the effort to ensure that models behave in ways that reflect human intentions and values—at the center of both technical research and public discussion (Amodei et al., 2016; Christiano et al., 2023; Kong et al., 2024; Bereska & Gavves, 2024; Sharkey et al., 2025; Rai et al., 2024).
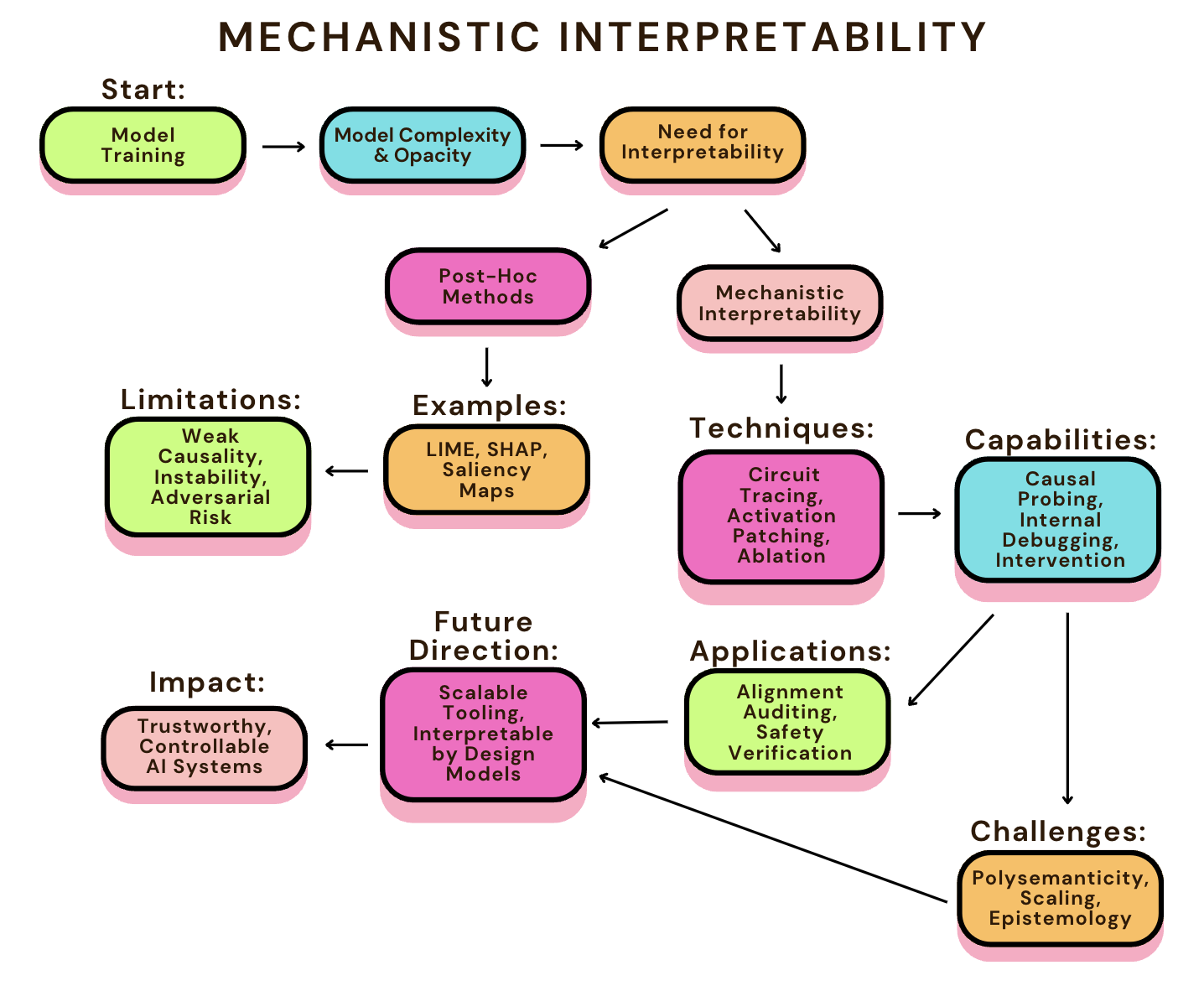
One of the key proposals in the effort to align and audit these models is the use of AI interpretability. Interpretability has been one of the main strategies proposed for alignment. The idea is simple: if we can understand how a model makes its decisions, we can better assess whether it’s behaving safely. Some work focuses on post-hoc explanations like LIME or SHAP (Ribeiro et al., 2016; Lundberg & Lee, 2017). Others, especially in mechanistic interpretability, attempt to look inside the model’s architecture—identifying which neurons, attention heads, or circuits contribute to specific behaviors (Olah et al., 2020; Nanda et al., 2023; Elhage et al., 2021a). These approaches are promising, but far from perfect. Post-hoc explanations are often inconsistent or easily manipulated (Adebayo et al., 2020; Slack et al., 2020).
Mechanistic work is labor-intensive and doesn’t yet scale well to frontier models. There’s also the deeper problem that many interpretability methods tell us stories about what the model might be doing, without strong evidence that those stories are true in a causal sense (Doshi-Velez & Kim, 2017; Vig et al., 2020). In addition, behavioral methods can leave latent misaligned or deceptive reasoning (Bharadwaj, 2025; Sheshadri et al., 2025). Beyond the technical challenges, there’s a disconnect between AI interpretability and older fields that have long dealt with explainability—like formal verification, social choice theory, and philosophy of science (Pearl, 2009; Bai, 2022; Mittelstadt et al., 2019). Alignment research doesn’t yet fully draw from these traditions, and this creates gaps in how we discuss about what constitutes as a “good” explanation, or how we validate that an explanation is meaningful.
Meanwhile, regulation is advancing more quickly than expected. The EU AI Act and similar proposals in the U.S. call for AI systems to provide understandable reasons for their decisions, especially in high-risk settings like criminal justice or finance (European Commission, 2021; Congress, 2022; Floridi et al., 2018; Raji et al., 2020). Industry has largely responded by leaning on behavioral alignment techniques like RLHF—methods that improve outputs but leave the internal logic of the system untouched (Selbst et al., 2018).
This paper examines the roll of interpretability in this context. We compare different approaches, discuss where they succeed and fail, and argue that internal transparency should be treated not as an optional extra, but as a basic requirement for building aligned systems. We also examine the limits of current methods, and consider the types of tools, benchmarks, and collaborations might help interpretability become more robust and reliable. Without solid foundations for understanding how models think, alignment risks becoming a surface-level fix for a deeper problem. Interpretability isn’t just about satisfying regulators or making outputs easier to explain—it’s about making sure we actually understand what these systems are doing before we trust them to act in the world.
2. Introduction to Model Interpretability
Interpretability has become a central concern in machine learning, but the term itself—and others like explainability and transparency— are often used without precision. This lack of clarity makes it difficult to evaluate which techniques actually help us understand models in a meaningful way.
In general, interpretability refers to how well a human can understand a model’s internal behavior—how inputs are processed, how decisions are formed, and why certain outputs are produced (Lipton, 2016). Explainability is often used more loosely to describe any attempt at generating a human-readable justification for a model’s output, even if that explanation does not reflect the model’s real internal logic (Rudin, 2019; Wachter et al., 2018). Transparency, meanwhile, is about access—whether we can inspect a model’s architecture, training data, or parameter choices (Gomez & Mouchère, 2023). Alignment goes one step further, asking whether the model behaves in line with human goals and values, particularly in unfamiliar or high-stakes settings (Carlsmith, 2024).
Table 1:Comparison between post-hoc and mechanistic interpretability approaches.
CriterionPost-HocMechanisticFocusExplains outputs after trainingExplains internal components/processesExamplesLIME, SHAP, Grad-CAMCircuits, Activation Patching, TracingNatureCorrelational, approximateCausal, structurally groundedScalabilityEasy to scale, low overheadResource-intensive, less scalableReliabilityRisk of misleading narrativesCloser to true model computation
Much of the confusion stems from how interpretability is implemented. Broadly, we can distinguish between two strategies. Intrinsic interpretability involves using models that are transparent by design—like decision trees or sparse linear models—where every step in the computation is accessible and understandable (Molnar, 2022; Besold et al., 2017). Post-hoc interpretability, on the other hand, involves explaining complex, black-box models after they have already been trained. These methods dominate real-world practice and include tools like LIME, SHAP, Integrated Gradients, and saliency maps (Kindermans et al., 2017).
Post-hoc methods are often helpful in building intuition, but they have frequently misleading. SHAP, for example, is widely used in industry to estimate which features contribute most to a model’s prediction. But it can be manipulated. In one study, a model was trained to base its decision on a sensitive attribute (like race), while SHAP was gamed to attribute importance to a more benign feature (like age), giving the illusion of fairness (Slack et al., 2020). This kind of explanation looks legitimate but hides what the model is actually doing—an especially dangerous failure mode when models are deployed in high-stakes environments.
Other methods, like Integrated Gradients, aim to offer more stable and theoretically grounded explanations by computing the average gradient between a baseline input and the real input (Vig et al., 2020). Integrated Gradients satisfies desirable properties like sensitivity and implementation invariance, but its effectiveness depends heavily on the choice of baseline and the smoothness of the gradient path—both of which are hard to tune in practice.
A newer approach, DL-Backtrace(Sankarapu et al., 2024), tries to overcome these limitations by tracing the influence of each layer on the final prediction in a consistent and deterministic way. Unlike gradient-based methods, it avoids reliance on input perturbations or baseline selection, making it more resistant to manipulation and more stable across architectures. DL-Backtrace has demonstrated promising results across vision, text, and tabular models, and offers a model-agnostic explanation strategy that can be applied accross across domains.
What all of these methods highlight is that interpretability is not just about generating a heatmap or a feature score— it is about whether we are actually uncovering something meaningful about the model’s behavior. Especially as models grow in size and complexity, we need to be clear about what kind of understanding a method offers: is it grounded in the model’s actual computation, or is it just a plausible story? If interpretability is going to contribute to alignment and safety, it needs to go beyond storytelling and provide explanations that we can test, trust, and build upon.
3. Mechanistic interpretability- Paradigm of Model Alignment
Mechanistic interpretability (MI) is a research approach aimed at uncovering the internal computations performed by neural networks. Rather than summarizing behavior through external correlations or approximations, MI seeks to identify the specific components—such as neurons, attention heads, or circuits—that causally contribute to particular model outputs (Olah et al., 2020; Nanda et al., 2023). The objective is to reverse-engineer models as functional systems, enabling a deeper understanding of how information is processed, decisions are made, and failures might arise.
Recent progress, particularly in transformer architectures, has demonstrated that certain model behaviors can be traced to interpretable substructures. The ”Circuits” research program has shown that individual attention heads may perform tasks such as token copying, syntactic tracking, or positional induction (Elhage et al., 2021b, a). Anthropic’s work further highlights how modular circuits within large models can execute operations like string comparison and arithmetic (Nanda et al., 2023). These findings suggest that even within high-parameter networks, small functional units may correspond to meaningful, testable computations. This opens the door to detecting internal failures—such as reward hacking or deceptive reasoning—that would not be apparent from output behavior alone (Bereska & Gavves, 2024; Amodei et al., 2016).
Importantly, mechanistic interpretability differs from post-hoc explanation in both scope and rigor. In contrast to post-hoc methods such as SHAP or LIME, which generate approximate input-output explanations, mechanistic interpretability investigates the actual structure of computation within the model (Rudin, 2019). Post-hoc methods have been shown to be sensitive to input perturbations, inconsistent across samples, and susceptible to adversarial manipulation (Slack et al., 2020; Lundberg & Lee, 2017). MI instead employs techniques such as activation patching and causal tracing to conduct controlled interventions on model components, providing empirical insight into internal mechanisms (Vig et al., 2020; Olah et al., 2020).
However, MI is not without limitations. A central challenge is polysemanticity—the observation that individual neurons or attention heads frequently encode multiple, unrelated features depending on context (Nanda et al., 2023; Olah et al., 2020). This ambiguity complicates efforts to assign precise semantic interpretations to specific components. As models scale in size and complexity, this issue becomes more pronounced. Research on large models like GPT-4 and LLaMA has shown that interpretable patterns often give way to entangled representations that defy simple causal decomposition (Elhage et al., 2021a; Diogo V. Carvalho, 2019). There are also epistemological concerns. Much interpretability work depends on human pattern recognition and informal labeling of features, which may introduce confirmation bias or overfitting to plausible but non-causal structures (Bai, 2022; Doshi-Velez & Kim, 2017). Without rigorous validation through ablation, counterfactual analysis, or intervention testing, interpretations may amount to “explanation theater”: compelling narratives that fail to hold up under scrutiny (Capeto, 2024; Kindermans et al., 2017).
In addition to epistemic challenges, there are significant resource and scalability bottlenecks. Mechanistic interpretability requires extensive computational resources, meticulous tracing, and highly skilled human researchers (Nanda et al., 2023). Although tools such as activation patching and circuit tracing have scaled in toy environments, they are not yet tractable for models with hundreds of billions of parameters (Joshi et al., 2025; Hatefi et al., 2025). This gap between theoretical capability and practical usability has led some critics to argue that MI may not scale to real world safety applications without major automation breakthroughs (Kcyras, 2024; Amodei et al., 2016; Lehalleur et al., 2025; Casademunt et al., 2025).
There are practical constraints in addition to conceptual challenges. Mechanistic analysis is time- and compute-intensive, requiring fine-grained probing, high-resolution instrumentation, and expert intuition. While activation patching and circuit tracing have been applied in smaller models, extending these techniques to frontier-scale systems remains challenging without significant automation and tooling support (Nanda et al., 2023). This gap between conceptual promise and practical feasibility raises important questions about the scalability of MI to real-world deployment scenarios (Kcyras, 2024; Amodei et al., 2016).
Nonetheless, MI offers capabilities that other alignment approaches currently lack. Most behavioral methods—such as reinforcement learning from human feedback (RLHF) or red teaming—focus on aligning outputs, without addressing how those outputs are generated. A model may behave acceptably while relying on unsafe or deceptive reasoning processes (Vig et al., 2020; Kong et al., 2024). MI provides tools for interrogating and, eventually, modifying these internal processes, enabling alignment at the level of reasoning rather than just performance. This makes MI a critical research direction for the alignment community. It reframes the challenge from shaping external behavior to understanding internal cognition. As argued in the Princeton Alignment Project and related work, interpretability is essential for building AI systems that are auditable, verifiable, and amenable to human oversight (Kcyras, 2024; Carlsmith, 2024).
Future progress in MI will likely depend on several factors: the development of scalable interpretability toolchains, more robust benchmarks, and closer integration with behavioral alignment and safety strategies. Hybrid approaches—where mechanistic insights inform or constrain behavioral fine-tuning—may offer a path forward (Hilton, 2024; Capeto, 2024). While MI alone cannot solve the alignment problem, it remains one of the most direct avenues for understanding and shaping how AI systems reason—and, ultimately, for ensuring that they do so in ways that serve human goals.
4. Positives: The Alignment Benefits of Interpretability
Interpretability should be increasingly viewed not as a diagnostic afterthought, but as a central mechanism for aligning AI systems with human intent (Diogo V. Carvalho & Cardoso, 2019; Molnar, 2022). By exposing and intervening on internal model representations, interpretability provides the tools to understand, evaluate, and modify neural networks from the inside—turning black-box systems into transparent, controllable agents (Bereska & Gavves, 2024; Kong et al., 2024; Vig et al., 2020).
Intervention and Falsifiability. One of the core contributions of mechanistic interpretability is the development of intervention-based techniques such as activation patching or causal tracing. These methods allow researchers to experimentally manipulate intermediate activations within a model to determine which components are causally responsible for specific behaviors (Olah et al., 2020). For example, by copying activations from a “clean” run into a corrupted context, one can isolate circuits or attention heads that restore correct outputs (Elhage et al., 2021a; Nanda et al., 2023). This approach provides a falsifiable framework for identifying and testing internal model hypotheses (Hilton, 2024; Bereska & Gavves, 2024). Auxiliary tools such as logit-difference comparisons and activation similarity metrics further support this framework, helping verify whether circuits generalize across varied tasks and inputs (Elhage et al., 2021b; Vig et al., 2020). Together, these elevate interpretability from exploratory inspection to a rigorous method for discovering alignment-relevant mechanisms under realistic deployment conditions (Nanda et al., 2023; Amodei et al., 2016).
Targeted Model Modification. Beyond analysis, interpretability enables targeted intervention. Techniques such as circuit editing, head ablation, or representation reweighting have been used to suppress undesired behaviors—such as toxicity or bias—while preserving task-relevant functionality (Meng et al., 2023; Maximilian Li & Nadeau, 2024; Vig et al., 2020). By pinpointing and modifying subgraphs responsible for misaligned behavior, interpretability enables precise behavioral corrections that avoid indiscriminate fine-tuning (Bereska & Gavves, 2024; Hilton, 2024; Malik et al., 2025). Importantly, mechanistic insights can also guide behavioral methods like RLHF or Constitutional AI. Rather than treating models as black boxes, these pipelines can be directed toward circuits revealed by interpretability, creating hybrid approaches that combine scalable behavioral alignment with causal guarantees (Hilton, 2024; Capeto, 2024).
Detecting Deceptive Alignment. Interpretability also provides a unique defense against deceptive alignment, where a model appears aligned during training but pursues hidden objectives at deployment (Hubinger et al., 2021; Bharadwaj, 2025). By tracing goal-directed circuits or identifying mechanisms for reward hacking, interpretability reveals latent failures that surface-level audits may overlook. This makes it a crucial complement to stress-testing or preference learning, which cannot reliably expose internal deception.
Blueprints from Toy Models. Studies on interpretable toy models illustrate the feasibility of mechanistic alignment. For instance, transformer models trained on mathematical tasks such as differentiation have revealed internal representations that perform symbolic operations, enabling researchers to reverse-engineer reasoning patterns (Tong et al., 2024; Elhage et al., 2021a). These controlled settings provide blueprints for regulating similar reasoning processes in larger and less constrained systems (Nanda et al., 2023).
Global Reasoning Pathways. Causal mediation analysis extends interpretability from isolated units to entire pathways of influence across layers. By tracing how internal variables mediate input–output relationships (Pearl, 2009; Vig et al., 2020), this method offers a global view of model reasoning and a route to aligning not just outputs, but the structure of decision-making itself (Bereska & Gavves, 2024; Maximilian Li & Nadeau, 2024; Hilton, 2024).
From Diagnostics to Design. Taken together, these techniques point toward a broader vision: interpretability as an interface for alignment. It enables proactive error detection, targeted adjustments, and structural verification of internal logic. In high-stakes domains, this transparency is essential for auditing, regulatory compliance, and long-term safety (Capeto, 2024; Bai, 2022; Pearl, 2009; Molnar, 2022; Marks, 2025). Crucially, interpretability should be integrated as a design principle, not an after-the-fact justification. Architectures built with modularity or sparsity to enhance interpretability are more likely to support human oversight without sacrificing performance (Bereska & Gavves, 2024; Tong et al., 2024; Rudin, 2019). Ultimately, interpretability narrows the gap between observable behavior and internal reasoning, enabling us to build systems that are not only effective but also trustworthy. By prioritizing interpretability in design and evaluation, alignment can progress from trial-and-error corrections to a causally grounded science of model reasoning (Doshi-Velez & Kim, 2017; Kcyras, 2024; Kong et al., 2024).
5. Limitations and Critiques of Interpretability
Table 2:Key limitations of interpretability methods.
CategoryLimitationRepresentationPolysemantic neurons, entangled features, unclear mapping to human conceptsMethodologyPost-hoc methods unstable/manipulable; risk of “explanation theater”EvaluationLack of standardized benchmarks; weak causal validationConceptualExplanations diverge from human categories (symbolic vs. subsymbolic)PracticalCompute- and expert-intensive; mostly low-level tasksRisk FactorsBias amplification, security leaks, explanation laundering
While interpretability is often positioned as essential for AI safety and transparency, it faces significant limitations—technical, conceptual, and practical. These challenges impact not only the reliability of specific methods, but also the broader epistemic claims made by the field.
5.1. Architectural and Representational Challenges
One core difficulty arises from the structure of modern neural networks themselves. In large transformer models, individual neurons or attention heads often encode multiple unrelated features depending on context—a phenomenon known as polysemanticity (Nanda et al., 2023; Olah et al., 2020).
This does not always imply superposition—polysemanticity may also arise from non-linear mixtures or compositional features (Chan, 2024). Anthropic’s “Toy Models of Superposition” illustrates how sparse features lead to overlapping representations (Elhage et al., 2022). Nanda emphasizes that while toy models are instructive, addressing superposition in real-world transformers remains an open challenge (Nanda, 2023). This superposition of meanings complicates efforts to assign stable, interpretable functions to individual units. As models like GPT-4 and LLaMA grow in depth and dimensionality, interpretability becomes increasingly brittle, with meaningful patterns often buried under distributed, entangled representations (Elhage et al., 2021a).
This complexity also creates a scale mismatch between human cognition and model reasoning. Interpretability tools are still poorly equipped to track long-range dependencies or emergent behavior across thousands of layers or billions of parameters (Vig et al., 2020). Projects like ”Interpretability Dreams” emphasize that mechanistic interpretability remains foundational, but current tools do not yet scale to the whole dynamics of frontier models (Nanda et al., 2023).
5.2. Methodological Limitations and Manipulability
Many interpretability methods are post-hoc and rely on surrogate explanations—feature attributions, saliency maps, probing classifiers—rather than revealing the actual causal mechanisms behind predictions (Rudin, 2019; Molnar, 2022). These methods can be easily manipulated. For example, LIME and SHAP have been shown to produce convincing yet misleading explanations in adversarial settings, allowing harmful or biased behavior to be concealed behind superficially plausible outputs (Slack et al., 2020; Srinivas & Fleuret, 2020). Recent work shows that sparse autoencoders can reliably disentangle features not only in MLP layers but also in attention outputs, suggesting practical paths for scaling superposition analysis (Kissane et al., 2024).
Moreover, such methods often lack theoretical guarantees. Explanations may correlate with observed outputs without reflecting the internal decision-making process (Kindermans et al., 2017). Many are also unstable: minor changes to inputs or random seeds can lead to significantly different explanations. Without rigorous validation through counterfactual testing, ablation studies, or causal probing, these methods risk offering illusions of understanding rather than genuine insight (Vig et al., 2020; Pearl, 2009; Méloux et al., 2025; Sutter et al., 2025).
5.3. Evaluation and Benchmarking Gaps
The interpretability field also lacks standardized benchmarks for evaluating the quality of the explanation. Benchmarks and reliable metrics are increasingly highlighted as fundamental for explainability and compliance (Seth & Sankarapu, 2025; Mueller et al., 2025). While qualitative studies rely on human judgment, quantitative metrics often focus on proxies such as sparsity, simplicity, or alignment with concept labels (Diogo V. Carvalho & Cardoso, 2019). These metrics do not necessarily correspond to causal validity or functional insight (Doshi-Velez & Kim, 2017). Calls for “role-calibrated” and context-sensitive interpretability reflect the need to move beyond shallow heuristics toward explanations that serve specific epistemic and safety purposes (Nanda et al., 2023; Mueller et al., 2025).
5.4. Linguistic and Conceptual Mismatches
Interpretability techniques often assume that internal model features can be mapped to classical linguistic categories—syntax, semantics, or discourse. However, evidence suggests that this mapping is frequently indirect or nonexistent (Olah et al., 2020; Vig et al., 2020). For instance, in Anthropic’s “tracing thoughts” experiments, features were identified that controlled conceptual transitions (e.g., Dallas → Texas → Austin)—yet these did not cleanly correspond to grammatical rules or semantic formalisms (Nanda et al., 2023).
This raises doubts about the generalizability of annotated circuits across languages, domains, or tasks (Elhage et al., 2021a). Interpretability that claims linguistic fidelity may instead reflect narrative approximations, especially in the absence of psycholinguistic grounding (Rudin, 2019; Vig et al., 2020). Without deeper engagement with linguistics and cognitive science, interpretability risks producing surface-level stories that resemble explanation but lack empirical support.
5.5. Confirmation Bias and “Explanation Theater”
There is a growing concern that interpretability research is susceptible to cognitive biases. Researchers may impose their own expectations onto neural patterns, over-interpreting noisy or ambiguous activations to fit preferred narratives (Bai, 2022; Doshi-Velez & Kim, 2017). This pattern-matching tendency can lead to “explanation theater”—convincing but unfounded justifications that appear rigorous without offering causal understanding (Kindermans et al., 2017; Pearl, 2009).
5.6. Security, Ethics, and Organizational Risks
Interpretability also carries risks when applied carelessly or in adversarial contexts. Making model internals more transparent can expose proprietary information, increase susceptibility to adversarial attacks, or allow malicious actors to game alignment audits (Molnar, 2022; Slack et al., 2020). Moreover, organizations may deliberately craft explanations to appear interpretable while concealing flaws—a practice known as explanation laundering (Srinivas & Fleuret, 2020).
5.7. Resource and Accessibility Constraints
In practice, interpretability demands significant resources—both in computational overhead and human labor. Tools that discover circuits or analyze activations often require expert manual effort to verify results (Olah et al., 2020; Elhage et al., 2021a). This raises equity concerns, as only well-resourced institutions can realistically perform high-fidelity interpretability at scale (Diogo V. Carvalho & Cardoso, 2019).
5.8. Shallow Scope of Current Interpretability Work
Most interpretability studies remain focused on syntactic or low-level semantic tasks, such as subject-verb agreement or next-token prediction. However, real-world understanding depends on discourse, pragmatics, and background knowledge—areas that current interpretability methods rarely address (Bai, 2022; Vig et al., 2020). Without extending to these higher levels of reasoning, interpretability may remain restricted to surface-level heuristics rather than genuinely human-aligned cognition (Rudin, 2019; Molnar, 2022).
5.9. Toward a More Grounded Interpretability Research Agenda
Interpretability is a necessary but incomplete solution to the alignment problem. Its potential to expose internal reasoning and support safe interventions is significant—but only if its limitations are recognized and addressed. Future progress will require rigorous validation protocols, scalable tooling, interdisciplinary collaboration, and a conceptual shift toward explanation methods that are grounded in causal, cognitive, and domain-relevant criteria (Doshi-Velez & Kim, 2017; Bai, 2022; Pearl, 2009).
Without these developments, interpretability risks becoming a collection of persuasive artifacts rather than a robust science of model understanding.
6. Comparative Analysis: Interpretability and Other Alignment Approaches
Interpretability plays a distinct and increasingly necessary role in the broader landscape of AI alignment. While most contemporary alignment methods—such as Reinforcement Learning from Human Feedback (RLHF), red teaming, and Constitutional AI—focus on shaping or auditing model outputs, interpretability targets the underlying mechanisms of model reasoning. This section compares the strengths and limitations of these approaches, and situates interpretability within the growing toolkit of alignment strategies.
6.1. RLHF and Behavioral Alignment
RLHF is currently the dominant alignment technique applied to large language models (Christiano et al., 2023). It aligns behavior by training models to conform to human preferences through reward modeling and policy optimization (Ziegler et al., 2020). While RLHF has been effective in improving output quality, it primarily addresses surface-level alignment. It does not verify whether internal reasoning processes are safe, truthful, or aligned with human values (Leike et al., 2018). As a result, models may exhibit inner misalignment—producing aligned outputs while internally pursuing misaligned objectives or heuristics (Stiennon et al., 2022; Hubinger et al., 2021; Kcyras, 2024; Barkan et al., 2025).
In contrast, interpretability offers tools for probing internal representations and identifying latent goals, deceptive heuristics, or emergent failure modes that may not manifest in observable behavior (Bereska & Gavves, 2024; Vig et al., 2020). This makes it a natural complement to RLHF—addressing questions of what the model ”is” trying to do, rather than only what it ”does”.
6.2. Red Teaming and Adversarial Stress Testing
Red teaming involves adversarially probing models to uncover vulnerabilities through carefully constructed prompts or stress scenarios (Perez et al., 2022). It is useful for testing behavioral robustness and identifying edge cases. However, red teaming often reveals that a failure occurred without explaining why it occurred (Ferreira et al., 2024). Interpretability can augment red teaming by analyzing the internal mechanisms that make a model susceptible to specific attacks—such as reliance on ambiguous token embeddings, exploit-prone circuits, or memorized failure patterns (Kong et al., 2024; Elhage et al., 2021b; Vig et al., 2020).
Used together, red teaming and interpretability enable both external diagnosis and internal causal tracing, offering a two-pronged strategy for identifying and addressing alignment risks.
Table 3:Interpretability techniques mapped to regulatory goals.
TechniqueGoalExampleActivation PatchingAccountabilityTest if protected attributes drive outputsCircuit EditingMitigationSuppress toxicity/bias without retrainingCausal MediationAuditabilityTrace decision pathways in safety-critical usePost-hoc AttributionComplianceExplain credit, insurance, hiring outcomesMechanistic DecompositionCertificationRegulator-facing proof of safety guarantees
6.3. Constitutional AI and Normative Constraints
Constitutional AI, developed by Anthropic, seeks to align models with high-level normative principles through supervised fine-tuning on constitutionally derived feedback (Anthropic, 2025). This approach aims to reduce reliance on human raters while promoting consistency with ethical standards (Bai et al., 2022). However, like RLHF, it operates at the level of model behavior and cannot confirm whether ethical constraints are reflected in the model’s internal structure or reasoning. Interpretability, in contrast, offers the possibility of validating whether such norms are mechanistically encoded or merely mimicked via surface compliance (Capeto, 2024; Kcyras, 2024; Vig et al., 2020).
6.4. Scalability and Generalization Tradeoffs
Behavioral alignment approaches are often preferred for their scalability. Techniques like RLHF and Constitutional AI generalize across tasks and domains with limited model-specific insight (Amodei et al., 2016; Leike et al., 2018). However, this scalability comes at a cost: models may pass alignment tests without robust guarantees about their internal states or decision-making pathways (Hubinger et al., 2021). Interpretability, although resource-intensive and currently limited in scale, provides the ability to inspect and validate alignment at the level of circuits, neurons, and attention heads (Bereska & Gavves, 2024; Elhage et al., 2021a). As model generalization increases, interpretability becomes less of a diagnostic tool and more of a structural requirement for alignment (Nanda et al., 2023).
6.5. Sequential and Hybrid Use Cases
One emerging paradigm is to apply interpretability post hoc, following alignment interventions such as RLHF. In this setting, interpretability serves to verify whether internal representations align with intended objectives, and whether harmful reasoning patterns remain latent despite behavioral improvements (Vig et al., 2020; Olah et al., 2020). For example, targeted interventions in attention weights or circuit pathways have revealed lingering risks such as reward hacking or policy drift—even in models that appear well-aligned at the output level (Meng et al., 2023; Maximilian Li & Nadeau, 2024). Interpretability thus becomes a prerequisite for safe surgical alignment and post-training auditability (Hilton, 2024; Elhage et al., 2021a).
6.6. Epistemic Rigor and Explanation Standards
Interpretability also differs from other alignment strategies in its epistemic orientation. Many alignment methods rely on human-centered assessments—such as user satisfaction scores, preference rankings, or ethical proxies—that are not necessarily grounded in the model’s actual behavior (Srinivas & Fleuret, 2020). Mechanistic interpretability prioritizes testable, manipulable, and causally valid explanations (Marconato et al., 2023; Bereska & Gavves, 2024). Rather than asking whether an explanation is persuasive, interpretability asks whether it is correct (Andrea Papenmeier & Seifert, 2022; Vig et al., 2020).
Some have argued that interpretability, particularly in its mechanistic form, is fundamentally a kind of causal discovery (Pearl, 2009; Geiger et al., 2025). From this perspective, the core challenge is identifying the internal pathways by which information flows, decisions are made, and goals are pursued (Nanda et al., 2023; Kong et al., 2024). This position interprets interpretability not as a competing method, but as the foundational scientific lens through which all other alignment techniques might be assessed and validated.
6.7. Complementarity Rather Than Substitution
Overall, interpretability distinguishes itself through its emphasis on internal understanding, causal structure, and model transparency. It is less mature, less scalable, and more technically demanding than many behavioral alignment strategies—but also uniquely capable of diagnosing and modifying the internal logic of AI systems (Rudin, 2019; Molnar, 2022; Vig et al., 2020). Alignment pipelines of the future are likely to combine interpretability with behavioral methods: RLHF and Constitutional AI for guiding surface behavior, and interpretability for ensuring internal coherence and reliability (Hilton, 2024; Nanda et al., 2023).
As models become more powerful and autonomous, alignment strategies that rely solely on behavioral feedback will become increasingly insufficient. Interpretability, while not a standalone solution, provides the tools to look beneath behavior and examine the reasoning processes that underlie it. In doing so, it supports a deeper, more verifiable form of alignment—one grounded in structure, not just outcome.
Hybrid pipelines and epistemic value.
In practice, behavioral methods can shape outputs at scale while interpretability verifies causal fidelity post hoc. For example, models tuned with RLHF or Constitutional AI can be examined with activation patching and mediation to detect reward hacking, deceptive alignment, or brittle circuits that pass surface tests. Unlike behavioral metrics, which emphasize persuasiveness, interpretability evaluates causal correctness, providing the epistemic backbone for trustworthy alignment.
7. Call to Action: Prioritising Interpretability in AI Development
Table 4:Comparison of AI Alignment Approaches. MI = Mechanistic Interpretability, RLHF = Reinforcement Learning from Human Feedback, Const. AI = Constitutional AI.
CriterionMIRLHFRed TeamingConst. AITransparencyHigh (internal)Low (outputs)Low (failures only)Medium (principles)Human SupervisionLow (experts)High (raters)High (testers)Medium (curation)ScalabilityMediumLowLowHighCausal UnderstandingYesNoNoNoRisk CoverageInner failuresBehavioralExploitsNorms
7.1. Scaling Interpretability Tools and Infrastructure
The development of scalable and rigorous interpretability tools must become a central objective for AI safety research. Techniques such as activation patching, causal tracing, and circuit decomposition have demonstrated their value in controlled settings and mid-scale transformer models (Elhage et al., 2021b; Maximilian Li & Nadeau, 2024; Olah et al., 2020). However, they are not yet feasible for deployment on frontier-scale systems involving hundreds of billions of parameters (Nanda et al., 2023; Hilton, 2024). Substantial investment is needed to automate interpretability pipelines, develop generalizable analysis frameworks, and establish open-source repositories of annotated circuits (Bereska & Gavves, 2024; Meng et al., 2023).
Interpretability tools must evolve beyond visualization toward building testable, manipulable, and causally validated models of internal computation (Pearl, 2009; Seth et al., 2025). Despite rapid progress, the field still lacks a concise, end-to-end tool that unifies intervention-based mechanistic interpretability (activation patching, circuit tracing, causal mediation) with causal validation, scalability, and auditable reporting. To address this, we in future plan to release a reproducible toolkit that standardizes these primitives and produces alignment-ready audit artifacts. Future progress will depend on consolidating research themes such as resolving superposition, developing scalable interpretability toolchains, and building collaborative infrastructure for alignment (Sharkey et al., 2022).
7.2. Integrating Interpretability into Model Design
Interpretability must be integrated earlier in the AI development lifecycle. Treating interpretability as a post-training diagnostic constrains its utility and limits its influence over system behavior. Instead, interpretability should inform architecture design, training objectives, and evaluation metrics from the outset (Hilton, 2024; Diogo V. Carvalho & Cardoso, 2019). Models built with modularity, sparsity, or architectural constraints that promote semantic clarity are more amenable to inspection and control without necessarily sacrificing performance (Bereska & Gavves, 2024; Tong et al., 2024; Rudin, 2019). Achieving this will require a rethinking of current engineering incentives—from maximizing performance under opacity to optimizing for transparency under constraint (Bai, 2022; Srinivas & Fleuret, 2020).
7.3. Expanding Interdisciplinary Collaboration
Interpretability research must engage more deeply with adjacent disciplines. Insights from cognitive science, linguistics, formal semantics, human factors, and epistemology are essential to developing tools that produce not only technical insights but usable understanding (Capeto, 2024; Hubinger et al., 2021). Without grounding in how humans process explanations or evaluate reasoning, interpretability outputs risk becoming uninterpretable themselves—data-rich but insight-poor (Vig et al., 2020; Hilton, 2024). Building interdisciplinary teams will be critical for ensuring that explanations are not only mechanically correct but also cognitively accessible and epistemically sound (Bai, 2022; Doshi-Velez & Kim, 2017).
7.4. Aligning Governance and Incentives
The broader alignment community must advocate for regulatory and institutional frameworks that incentivize interpretability. Policies such as the EU AI Act’s transparency mandates should be extended to include requirements for internal model documentation, circuit-level auditability, and third-party interpretability assessments in high-risk applications (Anthropic, 2025; Hilton, 2024; Bloom et al., 2025). Without governance pressure, short-term performance incentives will continue to displace long-term investments in interpretability infrastructure (Kcyras, 2024; Rudin, 2019). Interpretability must be seen as a compliance pathway—not just a research concern.
7.5. Raising Methodological Standards Within the Field
The interpretability community must uphold greater epistemic rigor and methodological discipline. To avoid the trap of “explanation theater,” researchers must prioritize empirical validation through causal interventions, counterfactual analysis, and robustness testing (Capeto, 2024; Slack et al., 2020). Establishing standard evaluation benchmarks and aligning interpretability outputs with alignment-relevant safety metrics is essential for transitioning from academic demonstrations to practical standards (Hilton, 2024; Bereska & Gavves, 2024; Pearl, 2009). Interpretability cannot become a vehicle for plausible narratives—it must remain grounded in testable claims and falsifiable insight (Andrea Papenmeier & Seifert, 2022).
Taken together, these changes represent a call to move interpretability from the periphery to the core of AI development. When treated as a design principle, interpretability empowers more than understanding—it enables control, auditability, and ultimately, trustworthy alignment.
8. Discussion and Broader Implications
Interpretability occupies a distinctive position within the broader AI alignment landscape. It offers more than technical insight—it provides an avenue toward causal understanding, internal auditing, and structured intervention (Bereska & Gavves, 2024; Kong et al., 2024; Nanda et al., 2023). However, its implications extend well beyond internal model mechanics. Interpretability intersects with domains of governance, philosophy of explanation, regulatory design, and public trust in increasingly consequential ways (Hilton, 2024; Capeto, 2024; Vig et al., 2020).
8.1. From Black-Boxes to Auditable Systems
Mechanistic interpretability signals a transition from opaque optimization systems to cognitively structured, editable artifacts. In high-stakes applications—such as healthcare, legal reasoning, or autonomous systems—this shift has critical implications for accountability. Transparent reasoning processes enable causal attribution in model failures, making it possible to assign responsibility and ensure due process in human-facing decision contexts (Bai, 2022; Diogo V. Carvalho & Cardoso, 2019). As a result, interpretability could reshape legal liability regimes and inform consent standards by grounding them in internal explanations rather than surface behavior (Hilton, 2024; Amodei et al., 2016).
8.2. Explanation Beyond Intuition
Interpretability also raises deep philosophical questions. Human explanations are generally symbolic, abstract, and narratively coherent; neural explanations are often distributed, mechanistic, and subsymbolic (Pearl, 2009; Bai, 2022). This disjunction challenges the assumption that model explanations can or should align neatly with human cognitive categories (Kong et al., 2024; Williams et al., 2025; Ayonrinde & Jaburi, 2025b, a). Bridging this gap requires epistemic humility: interpretability may illuminate internal processes, but those insights may not translate directly into concepts that humans intuitively understand (Capeto, 2024; Rudin, 2019). Therefore, interpretability must be pursued not only as a technical objective, but as a conceptual and communicative one.
8.3. Rethinking Model Architecture and Design
Interpretability also has the potential to shape how models are built. Current architectures tend to prioritize performance, often resulting in deeply entangled representations (Elhage et al., 2021a; Golechha & Dao, 2024) that resist decomposition and mechanistic inspection (Slack et al., 2020). By contrast, models designed with interpretability constraints—such as modularity, sparsity, or hierarchical structuring—may yield more transparent internal representations without sacrificing capability (Bereska & Gavves, 2024; Tong et al., 2024). This design orientation could also support the development of hybrid neuro-symbolic systems, combining the raw computational power of deep networks with structured, human-comprehensible representations (Hilton, 2024; Srinivas & Fleuret, 2020).
8.4. Geopolitical and Economic Dimensions
The lack of interpretability has strategic consequences. In a competitive global AI race, actors may resist transparency due to concerns over intellectual property or misuse by adversaries (Kcyras, 2024; Anthropic, 2025). However, opacity also increases systemic risk. Misaligned systems that cannot be interpreted or audited internally present not just technical failure modes, but civilizational-level threats. The development of third-party interpretability audits, publicly maintained benchmarks, and regulatory mandates could align economic incentives with safety goals—enabling transparency without requiring complete openness (Hilton, 2024; Doshi-Velez & Kim, 2017).
8.5. Cultural and Human Integration
Interpretability will also shape how AI systems are integrated into social and cultural life. In domains such as education, mental health, creativity, and personal assistance, the ability of an AI system to explain its reasoning will influence how humans engage with it (Capeto, 2024; Vig et al., 2020). Models capable of self-explanation may be seen as tools or collaborators. Uninterpretable models, by contrast, risk being treated as oracles—unquestioned when trusted, and irredeemable when failed. Interpretability thus plays a crucial role in calibrating trust, enabling moral delegation, and supporting the formation of social norms around AI (Kong et al., 2024; Pearl, 2009).
8.6. A Foundational Layer of Responsible AI
In sum, interpretability is not simply a technical specialization. It is foundational to how AI systems will be designed, regulated, understood, and trusted. It reshapes how we assign responsibility, how we evaluate truthfulness, and how we conceive of machine reasoning itself. Whether in law, policy, engineering, or human-computer interaction, interpretability offers the infrastructure for meaningful oversight in a world increasingly mediated by intelligent systems.
The question is not whether interpretability will matter, but whether it will be adopted in time—and with sufficient rigor—to guide the integration of AI into human society responsibly. Its future will determine whether AI systems become opaque engines of disruption or transparent collaborators in the advancement of human flourishing (Bereska & Gavves, 2024; Kcyras, 2024; Amodei et al., 2016).
9. Conclusion
Interpretability is not a secondary concern or a research curiosity—it is a foundation for building safe and reliable AI systems (Bereska & Gavves, 2024; Kong et al., 2024; Olah et al., 2020). While behavioral alignment strategies like RLHF, Constitutional AI, and red teaming have shown utility in shaping outputs to human preference (Stiennon et al., 2022; Bai et al., 2022; Hubinger et al., 2021), they leave untouched the internal mechanisms that produce those outputs in the first place (Kcyras, 2024; Hilton, 2024; Doshi-Velez & Kim, 2017). Interpretability addresses this gap. It reaches into the hidden computations of these systems and makes it possible to understand, verify, and—in some cases—intervene on how models reason (Elhage et al., 2021b, a).
However, that potential does not come easily. Neural networks encode features in overlapping, distributed ways that do not cleanly map to human concepts. Many explanations we extract are challenging to scale, hard to validate, or misleading when they mirror what we expect rather than what is real (Bai, 2022; Rudin, 2019). We also lack automated tools that can operate at the scale of today’s largest models (Capeto, 2024; Slack et al., 2020). Interpretability research has to face these challenges directly, and that includes the ethical and epistemological stakes of deciding what counts as a valid explanation (Hilton, 2024; Bai, 2022; Pearl, 2009). Explanations must not simply reassure—they must be grounded in causal evidence and open to scrutiny (Marconato et al., 2023; Andrea Papenmeier & Seifert, 2022; Diogo V. Carvalho & Cardoso, 2019).
Going forward, AI alignment will require more than just behavioral tuning or interpretability in isolation. It demands a joint approach: using interpretability as a design principle to shape how models are built and trained (Bereska & Gavves, 2024; Elhage et al., 2021b; Nanda et al., 2023), and applying behavioral methods like RLHF to guide external performance (Stiennon et al., 2022; Bai et al., 2022; Hubinger et al., 2021). The goal is not only to make models behave safely but to ensure they are internally structured in ways that are understandable, inspectable, and aligned with human intent (Kcyras, 2024; Hilton, 2024; Vig et al., 2020).
Interpretability is not a nice-to-have. It is a requirement for building systems we can audit, trust, and ultimately control (Kong et al., 2024; Bereska & Gavves, 2024; Pearl, 2009). Without it, alignment becomes a matter of hope. With it, we have a path to reasoning about AI in terms we can understand and shape. It makes possible a future where robust AI systems are not only effective but also transparent and aligned in a way that stands up to inspection, not just intention (Kcyras, 2024; Bereska & Gavves, 2024; Amodei et al., 2016).
10. Impact Statement
This position paper argues for interpretability as a design principle for alignment. Potential benefits include more transparent, auditable systems; compliance support under emerging regulation; and earlier detection of deceptive or misaligned reasoning. Risks include “explanation theater” from weakly validated methods, possible exposure of sensitive internals, and concentration of expertise in well-resourced labs. We advocate causal validation, rigorous benchmarks, and governance integration to mitigate these risks.