The transformer revolution changed how we process sequences and images, but its computational design never truly aligned with the structural nature of tabular data. Unlike text, where positional order defines meaning, or vision, where local patches form coherent spatial relationships, tabular data is both irregular and heterogeneous. Rows represent independent records, columns represent distinct semantic entities, and the relationship between them depends entirely on context.
The Problem of Scale in Tabular Learning
The transformer revolution changed how we process sequences and images, but its computational design never truly aligned with the structural nature of tabular data. Unlike text, where positional order defines meaning, or vision, where local patches form coherent spatial relationships, tabular data is both irregular and heterogeneous. Rows represent independent records, columns represent distinct semantic entities, and the relationship between them depends entirely on context.
When early Tabular Foundation Models (TFMs) like TabPFN and TabICL emerged, they introduced the promise of zero-shot generalization, the ability to make predictions on unseen tasks without retraining. But these architectures, while groundbreaking, struggled to scale. Dense attention layers quickly became computationally prohibitive as feature counts or row volumes grew, and long-range dependencies were often lost in the noise of fully connected attention graphs.
In practical enterprise settings, where datasets are wide, imbalanced, and high-dimensional, these models began to hit fundamental efficiency limits.
What was needed was an architecture that could retain the reasoning power of transformers while operating efficiently across scales, from small tabular datasets to massive enterprise-grade tables. Orion-MSP was built precisely to meet that need.
Rethinking Attention for Tabular Foundation Models
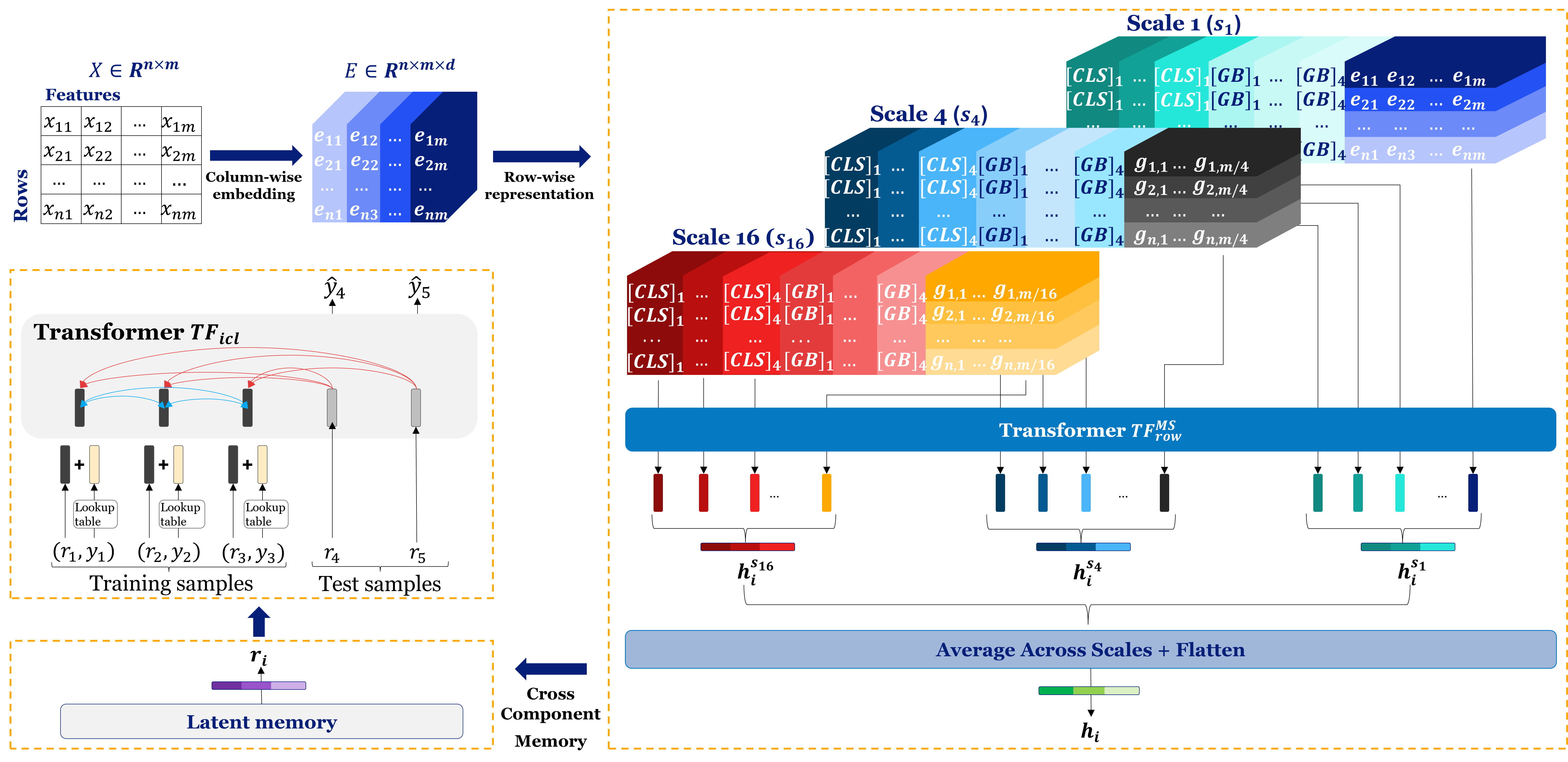
At its core, Orion-MSP (Multi-Scale Sparse Processor) reimagines how transformers reason about structured data. The model introduces a multi-scale sparse attention mechanism designed to capture both local and global dependencies without exploding in complexity.
Traditional attention mechanisms compute pairwise similarities across all tokens, resulting in quadratic cost with respect to input size. Orion-MSP breaks this pattern by introducing block-sparse attention, where only a subset of relevant tokens participate in the computation for each query. Instead of attending to all rows and columns simultaneously, the model dynamically identifies a smaller, contextually meaningful set of relationships.
This selective sparsity is implemented through row-wise and column-wise partitioning. Each row attends primarily to other rows within its statistical neighborhood, determined through feature similarity or learned clustering, while maintaining limited global connections that preserve overall dataset coherence.
The outcome is a model that behaves hierarchically: it understands local feature interactions within a record and long-range correlations across populations. This hybrid reasoning structure forms the foundation of Orion-MSP’s scalability.
Multi-Scale Processing: Learning Across Contexts
The “multi-scale” component of Orion-MSP refers to its hierarchical feature aggregation. Rather than treating all features and rows uniformly, the model processes information at different levels of abstraction. At the fine-grained level, Orion-MSP captures short-range relationships — interactions between features within a row or among nearby samples in embedding space.
At the coarse level, it aggregates these localized representations into a global latent memory inspired by Perceiver IO architectures. This latent memory acts as a persistent information hub that allows the model to reason over dataset-wide statistics and context without recomputing dense attention maps.
In practice, this means the model doesn’t just learn how features co-vary — it learns how those covariances change across the distribution. This gives Orion-MSP its ability to adapt to structured data where relationships evolve over time or between domains.
The combination of sparse attention and multi-scale reasoning allows Orion-MSP to reduce attention complexity from quadratic to near-linear while maintaining a high degree of expressivity. It learns effectively on both narrow, high-cardinality datasets and extremely wide tables without suffering from memory saturation.
Building Efficiency Through Hierarchical Contextualization
The model’s attention graph is contextually sparse, meaning that attention scores are computed only for meaningful relationships rather than all possible pairs. This enables Orion-MSP to scale linearly with dataset size in most cases, a substantial departure from the limitations of dense transformers.
Each layer in Orion-MSP follows a three-phase flow:
- Intra-row feature fusion — embedding and normalizing heterogeneous columns.
- Inter-row sparse attention — propagating information through similarity-based adjacency.
- Latent aggregation and compression — pooling multi-scale contexts into compact summaries.
This design enables the network to reason both statistically and semantically, striking a balance between detail and generalization. The result is an architecture that performs as well on small analytic tables as it does on extensive, complex industrial data.
Results:
Adaptation and Fine-Tuning Strategies
Orion-MSP supports a range of adaptation mechanisms designed to balance flexibility, efficiency, and performance. In zero-shot inference, the model uses its pretrained priors to predict directly on new tasks, conditioning on a small support set of examples without retraining. In supervised fine-tuning (SFT), it updates all parameters through end-to-end gradient optimization, ideal for large-scale, domain-specific adaptation. For efficient adaptation, Orion-MSP also integrates meta-learning where only specific layers are updated through episodic training and parameter-efficient fine-tuning (PEFT) via LoRA adapters. These adapters introduce low-rank trainable matrices that capture task-specific patterns while keeping the original model weights frozen, reducing both memory and compute overhead. This layered adaptation strategy makes Orion-MSP versatile: it can operate as a zero-shot inference engine for rapid experimentation or a fine-tuned backbone for production-scale deployment.
Calibration, Fairness, and Responsible Generalization
Orion-MSP’s training process integrates calibration and fairness diagnostics into its optimization loop. This ensures that performance metrics go beyond accuracy, addressing probabilistic reliability and bias. The model maintains statistically consistent uncertainty estimates through built-in regularization mechanisms. Its sparse multi-scale design also helps mitigate bias by preventing overrepresentation of dominant clusters in dense attention layers - a common issue in class-imbalanced datasets. When benchmarked, Orion-MSP shows consistently lower Expected Calibration Error (ECE) and higher stability across demographic subgroups compared to prior TFMs, making it more suitable for regulated industries where fairness and reliability are non-negotiable.
Performance and Empirical Findings
Extensive evaluation across 100+ datasets from TALENT, TabZilla, and OpenML-CC18 confirms Orion-MSP’s scalability and robustness. The model delivers higher accuracy and calibration stability than both TabPFN and TabICL, particularly in datasets with large feature spaces or non-Gaussian noise. More importantly, fine-tuning via LoRA adapters achieves comparable accuracy to full supervised fine-tuning while reducing compute requirements by nearly 80%. This makes Orion-MSP one of the most resource-efficient architectures in the current TFM ecosystem.
The Architectural Significance of Orion-MSP
Orion-MSP is more than a new transformer variant. It represents a philosophical shift in tabular modeling, from fixed-size, fully dense architectures toward adaptive, hierarchical, and context-aware reasoning. By aligning sparse computation with data topology, it shows that scaling foundation models for structured data doesn’t require brute-force parameter expansion, but architectural intelligence.
As TFMs continue to evolve, Orion-MSP serves as a blueprint for how tabular models can scale efficiently, maintain interpretability, and integrate fairness by design.

