Structured tabular data is the backbone of applications in healthcare, finance, and industrial analytics, and remains the most common data format in enterprises. Yet, despite this ubiquity, deep learning on tabular data has long lagged behind the breakthroughs achieved in domains such as natural language processing and computer vision.
Traditional approaches, particularly gradient-boosted decision trees (GBDTs) such as XGBoost, LightGBM etc, remain dominant due to their robustness against feature heterogeneity, small sample sizes, and the lack of spatial structure, challenges that standard neural networks often struggle to overcome. Deep models frequently underperform on tabular benchmarks due to the absence of spatial or temporal structure, rendering feature extraction less suitable for convolutional or sequential architectures. Moreover, tabular datasets often exhibit high heterogeneity, mixing numerical, categorical, and ordinal variables and suffer from missing values and skewed distributions, which violate many of the inductive biases that make deep learning successful in other modalities.
The TFM Paradigm and Operational Bottlenecks
Recently, the advent of tabular foundation models (TFMs) has begun to reshape this landscape. These models, including TabPFN, TabICL Orion-MSP, Orion-BiX etc, leverage large-scale pre-training on synthetic or massive tabular datasets to provide generalized learning capabilities. TabPFN, for example, excels at few-shot classification by approximating Bayesian inference, while TabICL scales in-context learning to large datasets.
Despite the strong promise of these TFMs, their practical adoption is severely limited by several operational frictions:
- Diverse Preprocessing Requirements: Each TFM demands a unique pipeline for data encoding, normalization, and missing-value handling, forcing practitioners to build bespoke systems for every model family.
- Fragmented APIs and Protocols: Models use diverse adaptation strategies, including zero-shot inference, Supervised Fine-Tuning (SFT), and Parameter-Efficient Fine-Tuning (PEFT/LoRA), making comparative experimentation laborious and error-prone.
- Evaluation Gaps: Unified assessment lacks deployment-relevant metrics like calibration of probability estimates and fairness across subgroups, hindering the assessment of model trustworthiness.
- Model Selection Complexity: Users face critical trade-off questions (e.g., memory vs. latency, calibration vs. tuning regime) that lack a unified experimental framework to resolve.
Introducing TabTune
To bridge this gap, we formally introduce TabTune by Lexsi, an open-source, scikit-learn-compatible framework engineered to deliver the canonical, production-ready workflow for TFM lifecycle management, directly addressing the diverse preprocessing and fragmented API challenges pervasive in this domain.
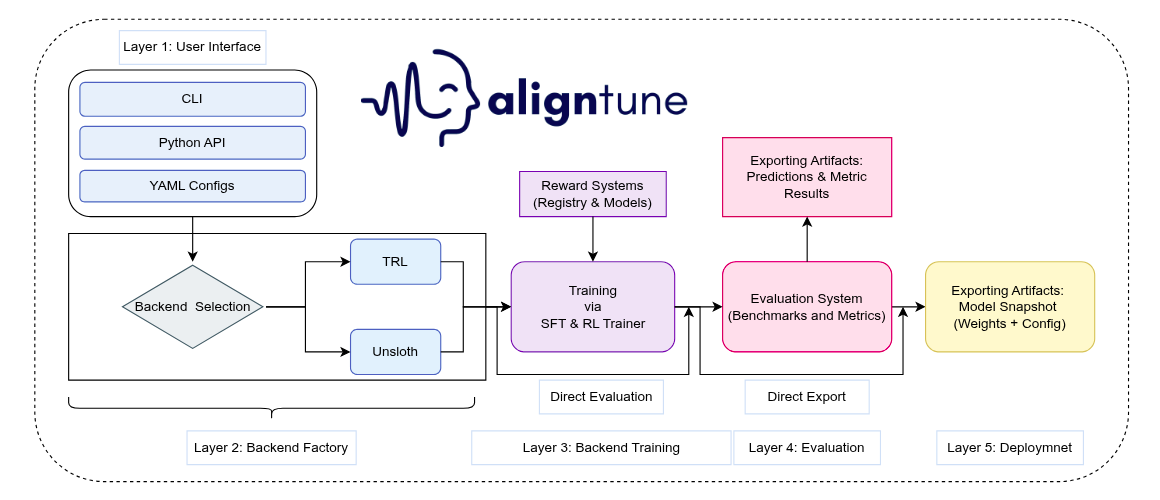
TabTune is architected not merely as a library, but as a unified orchestration layer (the TabularPipeline) enforcing standardization across seven diverse TFM models, including TabPFN (Prior-Fitted Network); TabICL, Orion-BiX & Orion-MSP (In-Context Learning), TabDPT (Denoising Transformer) and MITRA.
TabTune offers core functionalities that simplify and elevate TFM deployment:
- Single Interface:
Provides a consistent API for multiple TFM families, handling model-specific preprocessing internally. - Comprehensive Adaptation:
Supports the full spectrum of strategies: zero-shot inference, meta-learning, SFT, and PEFT (LoRA). - Built-in Diagnostics:
Includes metrics for Calibration (ECE, MCE, Brier score) and Fairness (SPD, EOD, EOpD) to enable holistic trustworthiness assessment. - Systematic Benchmarking:
Facilitates reproducible comparison of models and tuning strategies across standard suites (TALENT, OpenML-CC18) in a unified ranking framework.
TabTune enables practitioners to experiment rapidly and responsibly, utilizing consistent functions (e.g., .fit(), .predict(), .evaluate()), thereby transforming TFM deployment from a custom engineering task into a standardized process.
Systemic Abstraction and Adaptation Mechanisms
TabTune’s core technical contribution is the systemic abstraction of architectural variance, ensuring practitioners interact with a single, high-level API.
Dynamic Preprocessing and Data Fidelity
The DataProcessor module is the critical enabler, dynamically interrogating the selected TFM to instantiate the precise, model-aware data pipeline. This mechanism autonomously manages feature imputation, normalization, encoding, and embedding generation. For instance, it handles the conversion of features into integer-encoded tensors for TabPFN or orchestrates external embedding interfaces for ContextTab's semantics-aware components. This dynamic process guarantees data fidelity relative to the model's pre-training regime, minimizing manual configuration overhead.
The Adaptation Manifold: Optimization Pathways
The TuningManager codifies the necessary adaptation strategies, providing granular control over the trade-off between computational cost and task-specific specialization.
- Zero-Shot Inference: Exploits the model's large-scale pretrained knowledge base for immediate utility, operating entirely via forward passes without parameter updates. This modality is paramount for Orion-MSP, which achieves top performance on large benchmark suites without requiring training time.
- Meta-Learning (ML): A targeted, episodic fine-tuning process that samples support-query pairs to reinforce In-Context Learning (ICL) capabilities. This strategy empirically demonstrates the optimal balance between performance and generalization stability, significantly improving ranking consistency for models like Orion-MSP.
- Parameter-Efficient Fine-Tuning (PEFT/LoRA): Implements Low-Rank Adaptation (LoRA) by injecting trainable low-rank matrices (r = 8), ( = 16) into attention layers. PEFT achieves performance parity with Supervised Fine-Tuning (SFT) while reducing the fine-tuning memory footprint by 60–80%.
Validation and Deployment Integrity
The framework includes the TabularLeaderboard module, institutionalizing large-scale, reproducible benchmarking across over 100 datasets spanning TALENT, OpenML-CC18, and TabZilla.
- Calibration Reliability and Trustworthiness
Deployment in high-stakes domains mandates robust uncertainty quantification. TabTune integrates built-in diagnostics for Expected Calibration Error (ECE), Maximum Calibration Error (MCE), and Brier Score.
- Equitable Performance and Bias Mitigation
The evaluate_fairness() method enables systematic auditing of algorithmic bias by quantifying Statistical Parity Difference (SPD) and Equalized Odds Difference (EOD) across user-specified sensitive attributes. This functionality is critical for fulfilling compliance and ethical mandates in real-world deployment.
TabTune by Lexsi Labs is the established, performant, and reliable pathway to TFM operationalization in the industry. By resolving fundamental operational fragmentation and providing rigorous validation tools, we empower researchers and production engineers to make decisive transitions from research to deployment. We invite the global AI community to integrate this critical infrastructure and collaborate in defining the next generation of structured data intelligence.
TabTune Technical paper is accessible on Arxiv. -

Try TabTune released under MIT license, available on github. Let us know your thoughts.

<Lexsi Labs, Paris & Mumbai>